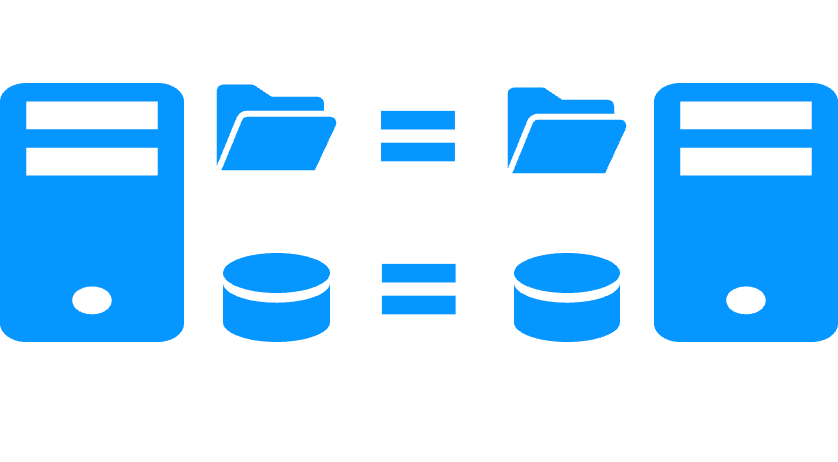
What is block-level disk replication?
Block-level disk replication (like with DRBD) means that only modifications inside a disk are replicated.
The volume of replicated data is not reduced to information modified by applications. Extra data are replicated like the meta data for managing the disk (list of free blocks, file system internal information).
There is a strong impact on the organization of application data. All data must be localized in the replicated disk. At least, it requires an application reconfiguration. Or, it is impossible if some data to replicate are in the system disk, because this disk must remain specific to each server.
The recovery time (RTO) increases with the file system recovery procedure on the replicated disk after a failover.
Finally, the solution is not easy to configure because skills are required to configure a special disk with a file system. Additionally, application skills are required to configure application data in the replicated disk.