The solution is described here: Podman: the simplest high availability cluster between two redundant servers - Evidian
Prerequisites
- You need the Podman application that you want to restart in SafeKit installed on 2 nodes (virtual machines or physical servers).
Package installation on Linux
-
Install the free version of SafeKit on 2 Linux nodes.
Note: the free trial includes all SafeKit features. At the end of the trial, you can activate permanent license keys without uninstalling the package.
-
After the download of safekit_xx.bin package, execute it to extract the rpm and the safekitinstall script and then execute the safekitinstall script
-
Answer yes to firewall automatic configuration
-
Set the password for the web console and the default user admin.

- Use aphanumeric characters for the password (no special characters).
- The password must be the same on both nodes.
Example with a simple container image
In this example, we will show how SafeKit could manage a nginx (web server) container, ie : replication of a directory accessed in the container and restart of the container on another node in case of failure.
Prerequisites
- Create a replicated directory on both nodes
Create a directory /replicated_dir_path that will be replicated by SafeKit and that will contain html pages served by nginx - Populate this directory with an initial html file on both nodes
cp index.html /replicated_dir_path - Create a container on both nodes
Create a nginx container on both nodes that bind the /replicated_dir_path directory to /usr/share/nginx/html:podman container create --name mynginx -v /replicated_dir_path:/usr/share/nginx/html -p 9011:80 nginx
SafeKit configuration
- Go to the step-by-step configuration section
- Create and configure a mirror.safe module
- Set a virtual IP address that will be switched in case of failure
- Set /replicated_dir_path as a replicated directory
- Put respectively in start_prim and stop_prim scripts: podman start mynginx and podman stop mynginx
Note: You may have to use "podman start --security-opt label=disable mynginx" with SE Linux. - Deploy and start the SafeKit mirror module
Tests
- Test access to nginx at http://vitual-ip:9011/index.html
- Test replication:
On the node in SafeKit PRIM state, add some other html files to the replicated directory:cp page.html /replicated_dir_path - Stop the mirror module on the node in SafeKit PRIM state
- Test that container has been restarted on the secondary node
- Test access to http://vitual-ip:9011/index.html and to http://vitual-ip:9011/page.html
1. Launch the SafeKit console
- Launch the web console in a browser on one cluster node by connecting to
http://localhost:9010. - Enter
adminas user name and the password defined during installation.
You can also run the console in a browser on a workstation external to the cluster.
The configuration of SafeKit is done on both nodes from a single browser.

To secure the web console, see 11. Securing the SafeKit web service in the User's Guide.

2. Configure node addresses
- Enter the node IP addresses, press the Tab key to check connectivity and fill node names.
- Then, click on
Save and applyto save the configuration.
If either node1 or node2 has a red color, check connectivity of the browser to both nodes and check firewall on both nodes for troubleshooting.
If you want, you can add a new LAN for a second heartbeat and for a dedicated replication network.
This operation will place the IP addresses in the cluster.xml file on both nodes (more information in the training with the command line).

3. Select a module
- In
New module, click on themirror.safemodule.
The console finds xxx.safe in the Application_Modules/generic/ directory on the server side if you dropped a module there during installation.

4. Configure the module
- Choose an
Automaticstart of the module at boot without delay. - Normally, you have a single
Heartbeatnetwork on which the replication is made. But, you can define a private network if necessary (by adding a LAN at step 2). - Enter a
Virtual IP address. A virtual IP address is a standard IP address in the same IP network (same subnet) as the IP addresses of both nodes.
Application clients must be configured with the virtual IP address (or the DNS name associated with the virtual IP address).
The virtual IP address is automatically switched in the event of a failure. - Check that the
Replicated directoriesare installed on both nodes and contain the application data.
Data and log replication are essential for a database..
You can create additional replicated directories as required. - Note that if a process name is displayed in
Monitored processes/services, it will be monitored with a restart action in case of failure. Configuring a wrong process name will cause the module to stop right after its start.
If you click on Advanced configuration, the userconfig.xml file is displayed (example with Microsoft SQL Server).

5. Edit scripts (optional)
start_primandstop_primmust contain starting and stopping of the Podman application (example provided for Microsoft SQL Server on the right).- You can add new services in these scripts.
- Check that the names of the services started in these scripts are those installed on both nodes, otherwise modify them in the scripts.
- On Windows and on both nodes, with the Windows services manager, set
Boot Startup Type = Manualfor all the services registered instart_prim(SafeKit controls the start of services instart_prim).

6. Communication encryption (optional)
- Keep encryption of communication between nodes.

7. Save and apply
Save and applythe configuration and scripts on both nodes.

8. Verify successful configuration
- Check the
Successmessage (green) on both nodes and click onMonitor modules.
On Linux, you may get an error at this step if the replicated directories are mount points. See this article to solve the problem.

9. Start the node with up-to-date data
- If node 1 has the up-to-date replicated directories, select it and start it
As primary.
When node 2 will be started, all data will be copied from node 1 to node 2.
If you make the wrong choice, you run the risk of synchronizing outdated data on both nodes.
It is also assumed that the Podman application is stopped on node 1 so that SafeKit installs the replication mechanisms and then starts the application in the start_prim script.
Use Start for subsequent starts: SafeKit retains the most up-to-date server. Starting As primary is a special start-up the first time or during exceptional operations.

10. Wait for the transition to ALONE (green)
- Node 1 should reach the ALONE (green) state, which means that the virtual IP is set and that the
start_primscript has been executed on node 1.
If ALONE (green) is not reached or if the application is not started, analyze why with the module log of node 1.
- click the "log" icon of
node1to open the module log and look for error messages such as a checker detecting an error and stopping the module. - click on
start_primin the log: output messages of the script are displayed on the right and errors can be detected such as a service incorrectly started.
If the cluster is in WAIT (red) not uptodate, STOP (red) not uptodate state, stop the WAIT node and force its start as primary.

11. Start node 2
- Start node 2 with its contextual menu.
- Wait for the SECOND (green) state.
Node 2 stays in the SECOND (orange) state while resynchronizing the replicated directories (copy from node 1 to node 2).
This may take a while depending on the size of files to resynchronize in replicated directories and the network bandwidth.
To see the progress of the copy, see the module log and the replication resources of node 2.

12. Verify that the cluster is operational
- Check that the cluster is green/green with Podman services running on the PRIM node and not running on the SECOND node.
Only changes inside files are replicated in real time in this state.
Components that are clients of Podman services must be configured with the virtual IP address. The configuration can be done with a DNS name (if a DNS name has been created and associated with the virtual IP address).

13. Testing
- Stop the PRIM node by scrolling down its contextual menu and clicking
Stop. - Verify that there is a failover on the SECOND node which should become ALONE (green).
- And with Microsoft Management Console (MMC) on Windows or with command lines on Linux, check the failover of Podman services (stopped on node 1 in the
stop_primscript and started on node 2 in thestart_primscript).
If ALONE (green) is not reached on node2 or if the application is not started, analyze why with the module log of node 2.
- click the "log" icon of
node2to open the module log and look for error messages such as a checker detecting an error and stopping the module. - click on
start_primin the log: output messages of the script are displayed on the right and errors can be detected such as a service incorrectly started.
If everything is okay, initiate a start on node1, which will resynchronize the replicated directories from node2.
If things go wrong, stop node2 and force the start as primary of node1, which will restart with its locally healthy data at the time of the stop.

14. Support
- For getting support, take 2 SafeKit
Snapshots(2 .zip files), one for each node. - If you have an account on https://support.evidian.com, upload them in the call desk tool.

15. If necessary, configure a splitbrain checker
- See below "What are the different scenarios in case of network isolation in a cluster?" to know if you need to configure a splitbrain checker.
- Go to the module configuration and click on
Checkers / Splitbrain(see image) to edit the splitbrain parameters. Save and applythe new configuration to redeploy it on both nodes (module must be stopped on both nodes to save and apply).
Parameters:
Resource nameidentifies the witness with a resource name:splitbrain.witness. You can change this value to identify the witness.Witness addressis the argument for a ping when a node goes from PRIM to ALONE or from SECOND to ALONE. Change this value with the IP of the witness (a robust element, typically a router).- Note: you can set several IPs separated by white spaces. Pay attention that the IP addresses must be accessible from one node but not from the other in the event of network isolation.

A single network
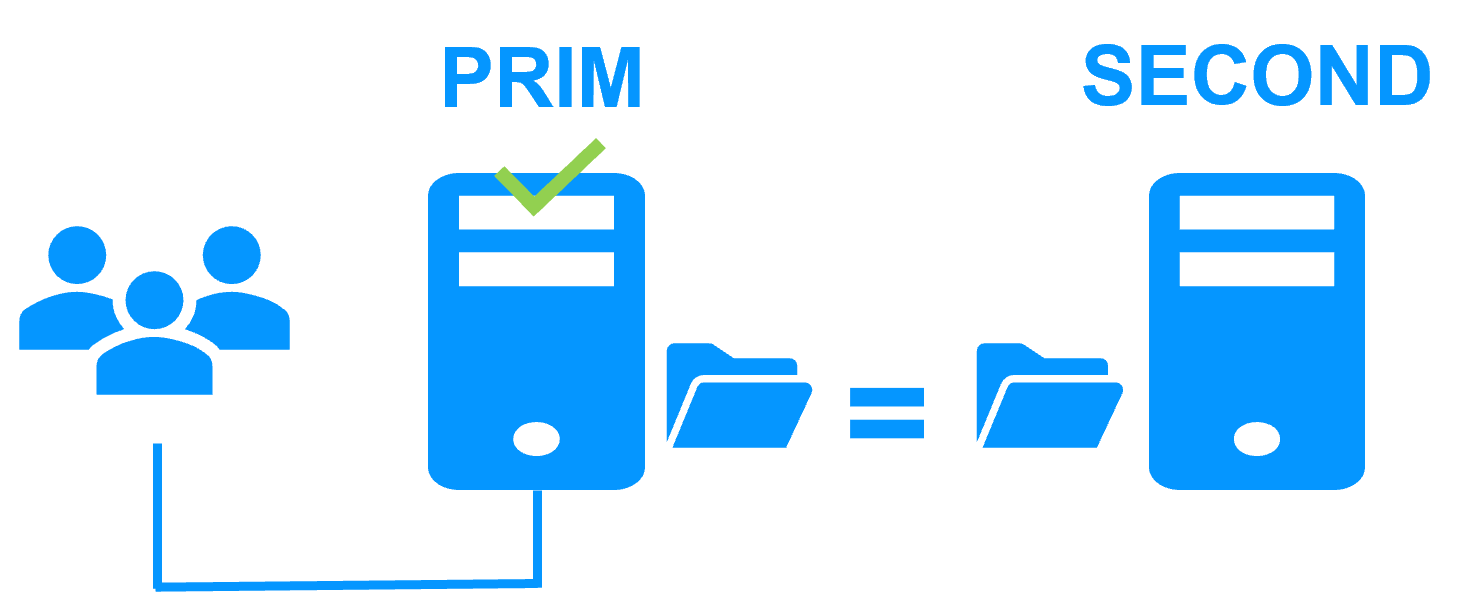
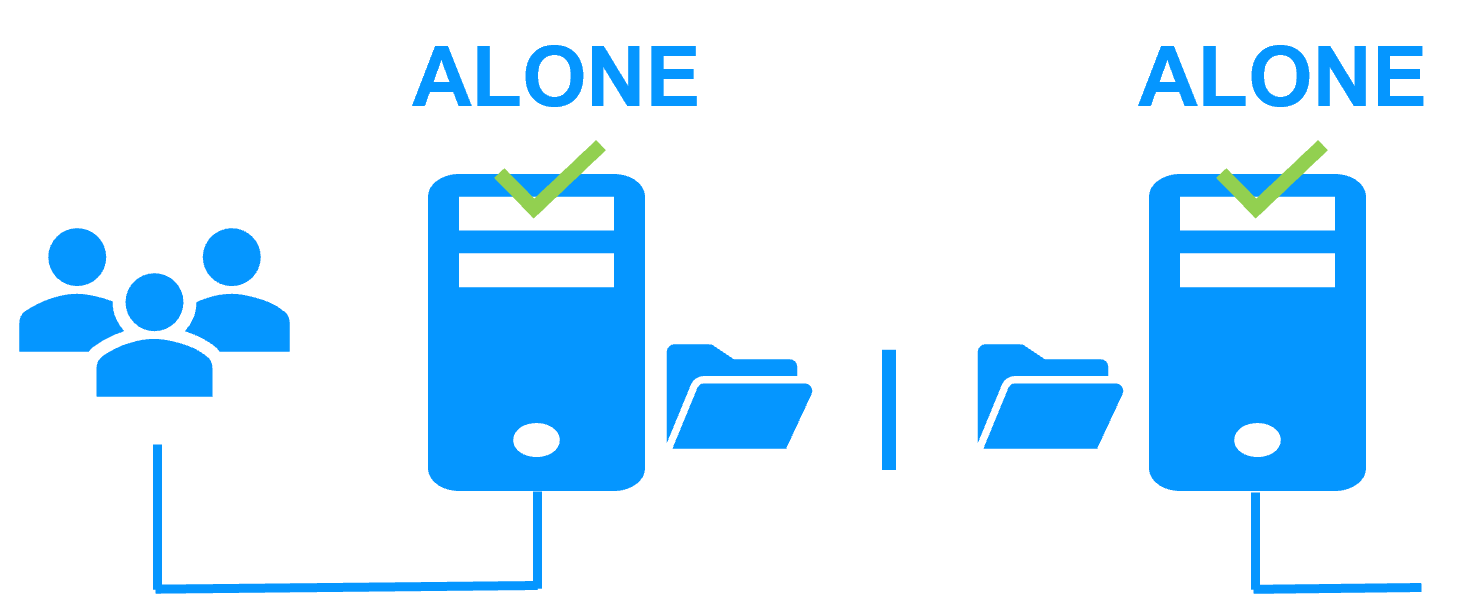
When there is a network isolation, the default behavior is:
- as heartbeats are lost for each node, each node goes to ALONE and runs the application with its virtual IP address (double execution of the application modifying its local data),
- when the isolation is repaired, one ALONE node is forced to stop and to resynchronize its data from the other node,
- at the end the cluster is PRIM-SECOND (or SECOND-PRIM according the duplicate virtual IP address detection made by Windows).
Two networks with a dedicated replication network
When there is a network isolation, the behavior with a dedicated replication network is:
- a dedicated replication network is implemented on a private network,
- heartbeats on the production network are lost (isolated network),
- heartbeats on the replication network are working (not isolated network),
- the cluster stays in PRIM/SECOND state.
A single network and a splitbrain checker
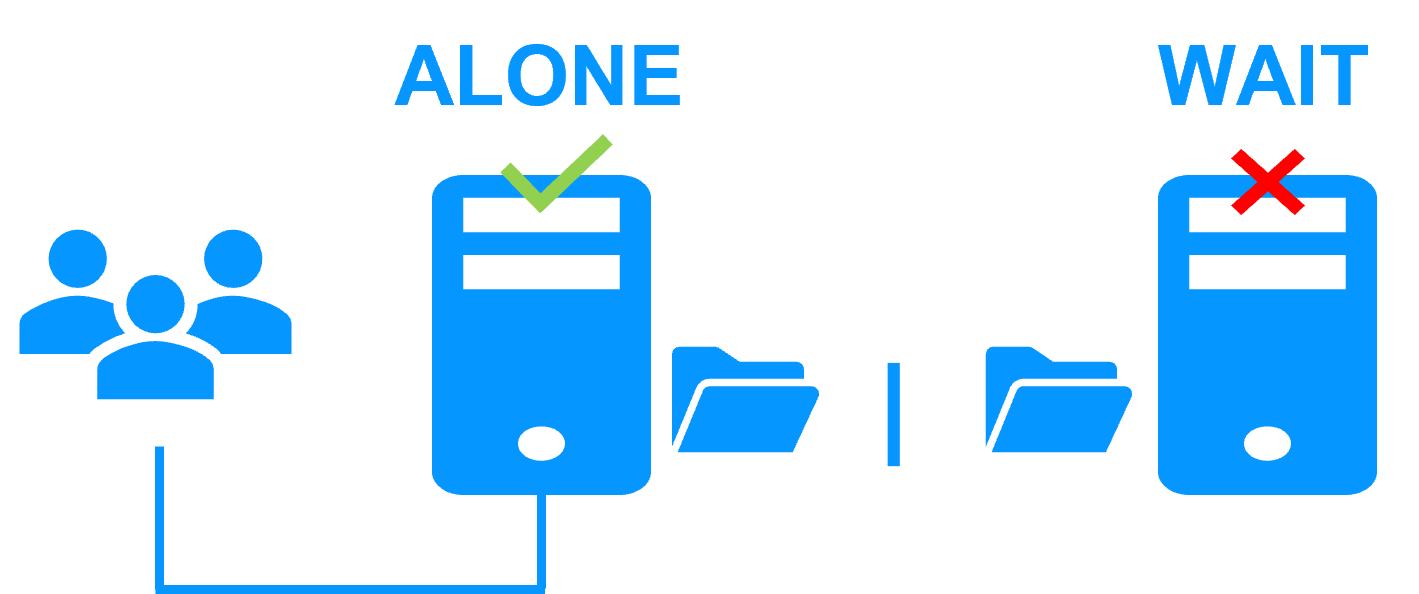
When there is a network isolation, the behavior with a split-brain checker is:
- a split-brain checker has been configured with the IP address of a witness (typically a router),
- the split-brain checker operates when a server goes from PRIM to ALONE or from SECOND to ALONE,
- in case of network isolation, before going to ALONE, both nodes test the IP address,
- the node which can access the IP address goes to ALONE, the other one goes to WAIT,
- when the isolation is repaired, the WAIT node resynchronizes its data and becomes SECOND.
Note: If the witness is down or disconnected, both nodes go to WAIT and the application is no more running. That's why you must choose a robust witness like a router.
Internals of a SafeKit / Podman high availability cluster with synchronous replication and failover
Go to the Advanced Configuration tab in the console, for editing these filesInternal files of the Linux mirror.safe module
userconfig.xml (description in the User's Guide)<!DOCTYPE safe>
<safe>
<service mode="mirror" defaultprim="alone" maxloop="3" loop_interval="24" failover="on">
<!-- Server Configuration -->
<!-- Names or IP addresses on the default network are set during initialization in the console -->
<heart pulse="700" timeout="30000">
<heartbeat name=”default” ident=”flow”/>
</heart>
<!-- Virtual IP Configuration -->
<!-- Replace
* VIRTUAL_TO_BE_DEFINED by the name/IP of your virtual server
-->
<vip>
<interface_list>
<interface check="on" arpreroute="on">
<real_interface>
<virtual_addr addr="VIRTUAL_TO_BE_DEFINED" where="one_side_alias"/>
</real_interface>
</interface>
</interface_list>
</vip>
<!-- Software Error Detection Configuration -->
<!-- Replace
* PROCESS_NAME by the name of the process to monitor
-->
<errd polltimer="10">
<proc name="PROCESS_NAME" atleast="1" action="restart" class="prim" />
</errd>
<!-- File Replication Configuration -->
<rfs mountover="off" async="second" acl="off" nbrei="3" >
<replicated dir="/test1replicated" mode="read_only"/>
<replicated dir="/test2replicated" mode="read_only"/>
</rfs>
<!-- User scripts activation -->
<user nicestoptimeout="300" forcestoptimeout="300" logging="userlog"/>
</service>
</safe>
#!/bin/sh
# Script called on the primary server for starting application
# For logging into SafeKit log use:
# $SAFE/safekit printi | printe "message"
# stdout goes into Application log
echo "Running start_prim $*"
res=0
# Fill with your application start call
if [ $res -ne 0 ] ; then
$SAFE/safekit printe "start_prim failed"
# uncomment to stop SafeKit when critical
# $SAFE/safekit stop -i "start_prim"
fi
#!/bin/sh
# Script called on the primary server for stopping application
# For logging into SafeKit log use:
# $SAFE/safekit printi | printe "message"
#----------------------------------------------------------
#
# 2 stop modes:
#
# - graceful stop
# call standard application stop
#
# - force stop ($1=force)
# kill application's processes
#
#----------------------------------------------------------
# stdout goes into Application log
echo "Running stop_prim $*"
res=0
# default: no action on forcestop
[ "$1" = "force" ] && exit 0
# Fill with your application stop call
[ $res -ne 0 ] && $SAFE/safekit printe "stop_prim failed"