The solution is described here: Hyper-V cluster without shared storage on a SAN - Evidian
Prerequisites
- You need the Hyper-V role installed on 2 Windows nodes (embedded for free in all Windows versions including Windows for PC).
- You need your critical applications installed inside one or more virtual machines.
- As the failover script imports a virtual machine on the secondary Hyper-V, be careful on Hyper-V settings and processor compatibility between both nodes.
Package installation on Windows
-
Download the free version of SafeKit on 2 Windows nodes.
Note: the free version includes all SafeKit features. At the end of the trial, you can activate permanent license keys without uninstalling the package.
-
To open the Windows firewall, on both nodes start a powershell as administrator, and type
c:/safekit/private/bin/firewallcfg add -
To initialize the password for the default admin user of the web console, on both nodes start a powershell as administrator, and type
c:/safekit/private/bin/webservercfg.ps1 -passwd pwd
- Use aphanumeric characters for the password (no special characters).
- pwd must be the same on both nodes.
-
Exclude from antivirus scans C:\safekit\ (the default installation directory) and all replicated folders that you are going to define.
Antiviruses may face detection challenges with SafeKit due to its close integration with the OS, virtual IP mechanisms, real-time replication and restart of critical services.
Module installation on Windows
-
Download the hyperv.safe module.
The module is free. It contains the files userconfig.xml and the restart scripts.
- Put hyperv.safe under C:\safekit\Application_Modules\generic\.
The Hyper-V configuration is presented with a virtual machine named VM1 and containing the application to restart in case of failure.
You will have to repeat this configuration for all VMs that you want to replicate and to restart. SafeKit supports up to 32 virtual machines.
1. Prerequisites
The VM1 virtual machine files (VM1 configuration file, virtual hard disk...) must be put in a same folder: this folder will be replicated by SafeKit.
Make sure the virtual switch name(s) referenced by the virtual machine exist on both Hyper-V servers and corresponds to the same physical network.
It is important that all the files representing a VM (Virtual Machines/, Virtual Hard Disks/, .vmcx, .vmgs, .vmrs, .vhdx, ...) are in the same directory replicated by SafeKit. Else your VM will not reboot after replication. If you are not sure, take a snapshot or your VM before starting the procedure.
If all the files of VM1 are not in the same folder, use Hyper-V manager:
- Export VM1 in a folder, for example in D:\Repli-Hyper-V
- This export will create a folder D:\Repli-Hyper-V\VM1\ containing all VM1 files
- Remove VM1 from the inventory of Hyper-V manager
- Import VM1, previously exported, into Hyper-V manager
VM1 should only be created on a single node. The only thing to create on the other node is the VM1 directory (D:\Repli-Hyper-V\VM1\).
2. Launch the SafeKit console
- Launch the web console in a browser on one cluster node by connecting to
http://localhost:9010. - Enter
adminas user name and the password defined during installation.
You can also run the console in a browser on a workstation external to the cluster.
The configuration of SafeKit is done on both nodes from a single browser.

To secure the web console, see 11. Securing the SafeKit web service in the User's Guide.

3. Configure node addresses
- Enter the node IP addresses, press the Tab key to check connectivity and fill node names.
- Then, click on
Save and applyto save the configuration.
If either node1 or node2 has a red color, check connectivity of the browser to both nodes and check firewall on both nodes for troubleshooting.
If you want, you can add a new LAN for a second heartbeat and for a dedicated replication network.
This operation will place the IP addresses in the cluster.xml file on both nodes (more information in the training with the command line).

4. Select a module
- In
New module, click on thehyperv.safemodule.
The console finds xxx.safe in the Application_Modules/generic/ directory on the server side if you dropped a module there during installation.

5. Configure the module
- Choose an
Automaticstart of the module at boot without delay. - Normally, you have a single
Heartbeatnetwork on which the replication is made. But, you can define a private network if necessary (by adding a LAN at step 3). - Put in
VM_PATH, the root path of the replicated directory (D:\Repli-Hyper-V). - Enter in
VM_NAME, the name of the virtual machine (VM1).
We assume that all VM1 files are in D:\Repli-Hyper-V\VM1\ (see prerequisites). This directory will be replicated in real-time by SafeKit.
The NORMAL_STOP and FORCE_STOP values can be "stop", "save" or "off":
- "
stop" shutdowns the VM when the module is stopped. - "
save" saves the current state of the VM (suspend) when the module is stopped. - "
off" turns off the VM (power off) when the module is stopped.
"stop" is recommended because it causes the shutdown then the reboot of the VM when the module is stopped and restarted. Thus, if the application inside the VM fails, it is restarted.
This will be the case, for example, when switching between primary and secondary roles.
You do not need to configure a virtual IP address. VM1 will be rebooted on the secondary Hyper-V with its physical IP address, and this IP address will be rerouted.

6. Custom checker to detect VM malfunction
The custom checker sends heartbeat messages from the host to the VM at regular intervals. It is then the job of the Hyper-V Heartbeat Service installed in the VM to send a response to each of these heartbeat messages.
If the Hyper-V Heartbeat Service does not respond to the message (VM locked up, crashed or ceased to function), then the custom checker executes an action to restart the VM on the same Hyper-V node or on the other.
- Click on
Checkers / Custom(see image). - Just set a name of your choice in
Resource name(example VM1).Resource nameidentifies the virtual machine with a resource name in SafeKit:custom.VM1. - With
restartinAction, the VM is restarted on the same Hyper-V node. After 3 unsuccessful restarts in 24 hours, the SafeKit hyperv module stops on the primary node and there is a failover of the VM on the secondary node. - If you set
stopstartinAction, there is a direct failover on the other Hyper-V node as soon as the VM does not respond to heartbeats.
For maintenance, if you want to stop the virtual machine, the custom checker will restart it automatically. To avoid that, you can temporarly suspend the checker. Or you can remove it by deleting the configuration line in the console.
It’s the same when you want to restore a checkpoint. Hyper-V will stop the VM to perform the operation, and the VM checker may react negatively by automatically restarting the VM. To avoid this, suspend the checker before proceeding with the operation.

7. Edit scripts (optional)
- Do not edit scripts.
8. Communication encryption (optional)
- Keep encryption of communication between nodes.

9. Save and apply
Save and applythe configuration and scripts on both nodes.

10. Verify successful configuration
- Check the
Successmessage (green) on both nodes and click onMonitor modules.

11. Start the node with up-to-date data
- If node 1 has the up-to-date replicated directory for
VM1/, select it and start itAs primary.
When node 2 will be started, all data will be copied from node 1 to node 2.
If you make the wrong choice, you run the risk of synchronizing outdated data on both nodes.
It is also assumed that VM1 is stopped on node 1 so that SafeKit installs the replication mechanisms and then starts VM1 in the start_prim script.
Use Start for subsequent starts: SafeKit retains the most up-to-date server. Starting As primary is a special start-up the first time or during exceptional operations.

12. Wait for the transition to ALONE (green)
- Node 1 should reach the ALONE (green) state, which means that the
start_primscript has been executed on node 1.
If ALONE (green) is not reached or if VM1 is not started, analyze why with the module log of node 1.
- click the "log" icon of
node1to open the module log and look for error messages such as a checker detecting an error and stopping the module. - click on
start_primin the log: output messages of the script are displayed on the right and errors can be detected such as VM1 incorrectly started.
If the cluster is in WAIT (red) not uptodate, STOP (red) not uptodate state, stop the WAIT node and force its start as primary.

13. Start node 2
- Start node 2 with its contextual menu.
- Wait for the SECOND (green) state.
Node 2 stays in the SECOND (orange) state while resynchronizing the replicated directories (copy from node 1 to node 2).
This may take a while depending on the size of files to resynchronize in replicated directories and the network bandwidth.
To see the progress of the copy, see the module log and the replication resources of node 2.
When using Hyper-V differencing disks, only the differencing disk needs resynchronization after the initial sync, saving time for large virtual hard disks.

14. Verify that the cluster is operational
- Check that the cluster is green/green with
VM1running on the PRIM node and not running on the SECOND node.
Only changes inside files are replicated in real time in this state.

15. Testing
- Stop the PRIM node by scrolling down its contextual menu and clicking
Stop. - Verify that there is a failover on the SECOND node which should become ALONE (green).
- Check with Hyper-V manager that
VM1is running on node 2.
If ALONE (green) is not reached on node2 or if VM1 is not started, analyze why with the module log of node 2.
- click the "log" icon of
node2to open the module log and look for error messages such as a checker detecting an error and stopping the module. - click on
start_primin the log: output messages of the script are displayed on the right and errors can be detected such as VM1 incorrectly started.
As the start_prim script imports the virtual machine on node 2, the failover can fail because of Hyper-V settings (see this article).
If everything is okay, initiate a start on node1, which will resynchronize the replicated directories from node2.
If things go wrong, stop node2 and force the start as primary of node1, which will restart with its locally healthy data at the time of the stop.

16. Automatic restart if a critical service fails inside the VM
If you want an automatic restart or failover when a critical service inside the VM fails, you can configure the Recovery properties of the service (see image).
First you must configure the custom checker previously described.
And then in Microsoft Service Manager inside the VM, select your critical service and in the recovery property of the service, you just have to configure shutdown of the VM when the critical service fails.
For that, in the Recovery options of your critical service, choose "Run a Program" on failures and in Run program options, set"C:\Windows\System32\shutdown.exe" and in "Command line parameters", set /s /c "service fails".
Of course, you can implement more subtle recovery with your own scripts. But just be aware that shutting down the VM will enable the custom checker in the host. The custom checker will detect that the Hyper-V heartbeat is no more responding and will restart the VM on the same Hyper-V server or will make a failover on the other Hyper-V server (depending on its configuration).
To test the feature, use Task Manager and kill the process (End task) associated to the critical service. A clean stop of the service through Service Manager or the "net stop" command does not trigger the recovery action inside Windows Service Manager.

17. Remove the start of VM1 in Hyper-V at boot
- In Hyper-V manager, configure VM1 with Automatic Start Action=nothing.
SafeKit controls the start and the stop of the VM on one node or the other.

18. Support
- For getting support, take 2 SafeKit
Snapshots(2 .zip files), one for each node. - If you have an account on https://support.evidian.com, upload them in the call desk tool.

19. If necessary, configure a splitbrain checker
- See below "What are the different scenarios in case of network isolation in a cluster?" to know if you need to configure a splitbrain checker.
- Go to the module configuration and click on
Checkers / Splitbrain(see image) to edit the splitbrain parameters. Save and applythe new configuration to redeploy it on both nodes (module must be stopped on both nodes to save and apply).
Parameters:
Resource nameidentifies the witness with a resource name:splitbrain.witness. You can change this value to identify the witness.Witness addressis the argument for a ping when a node goes from PRIM to ALONE or from SECOND to ALONE. Change this value with the IP of the witness (a robust element, typically a router).- Note: you can set several IPs separated by white spaces. Pay attention that the IP addresses must be accessible from one node but not from the other in the event of network isolation.
A single network
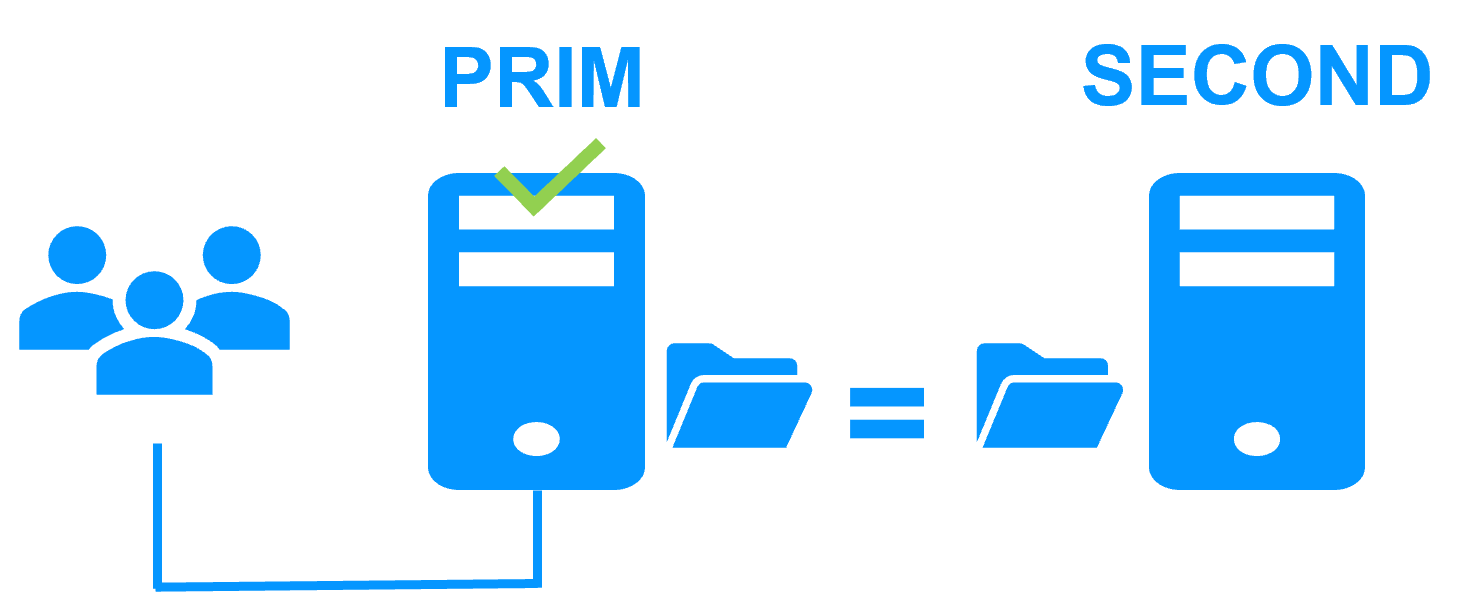
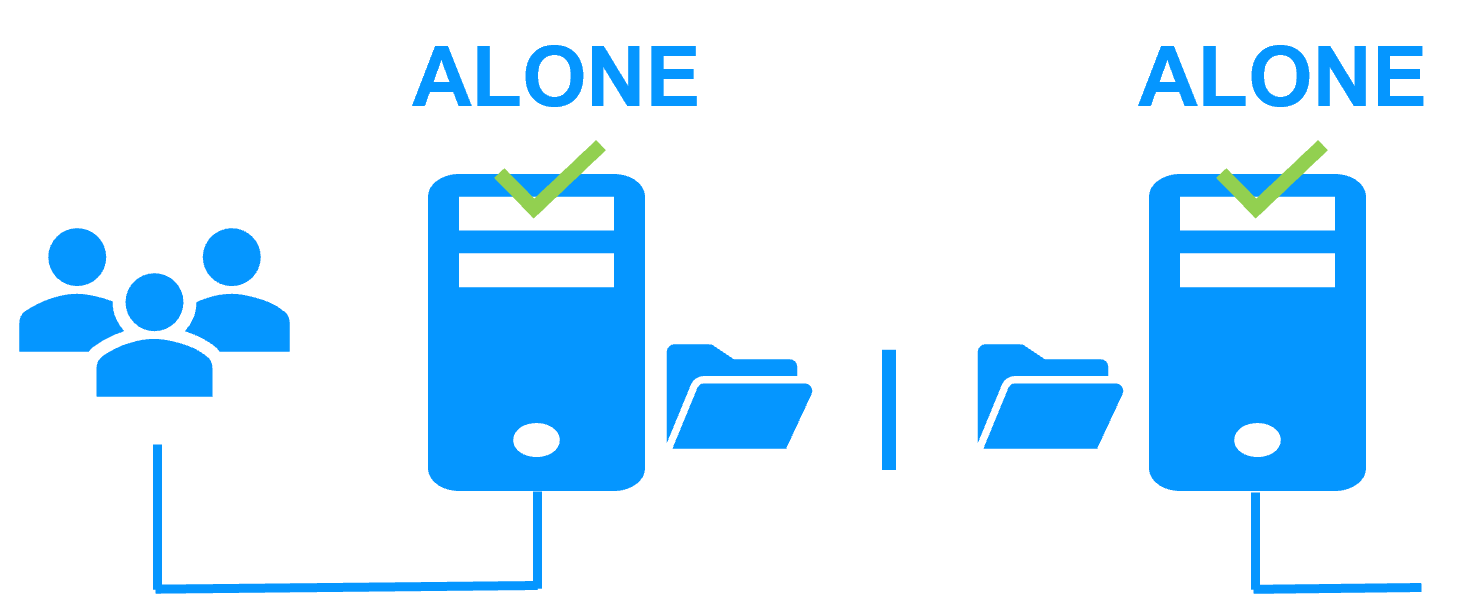
When there is a network isolation, the default behavior is:
- as heartbeats are lost for each node, each node goes to ALONE and runs the application with its virtual IP address (double execution of the application modifying its local data),
- when the isolation is repaired, one ALONE node is forced to stop and to resynchronize its data from the other node,
- at the end the cluster is PRIM-SECOND (or SECOND-PRIM according the duplicate virtual IP address detection made by Windows).
Two networks with a dedicated replication network
When there is a network isolation, the behavior with a dedicated replication network is:
- a dedicated replication network is implemented on a private network,
- heartbeats on the production network are lost (isolated network),
- heartbeats on the replication network are working (not isolated network),
- the cluster stays in PRIM/SECOND state.
A single network and a splitbrain checker
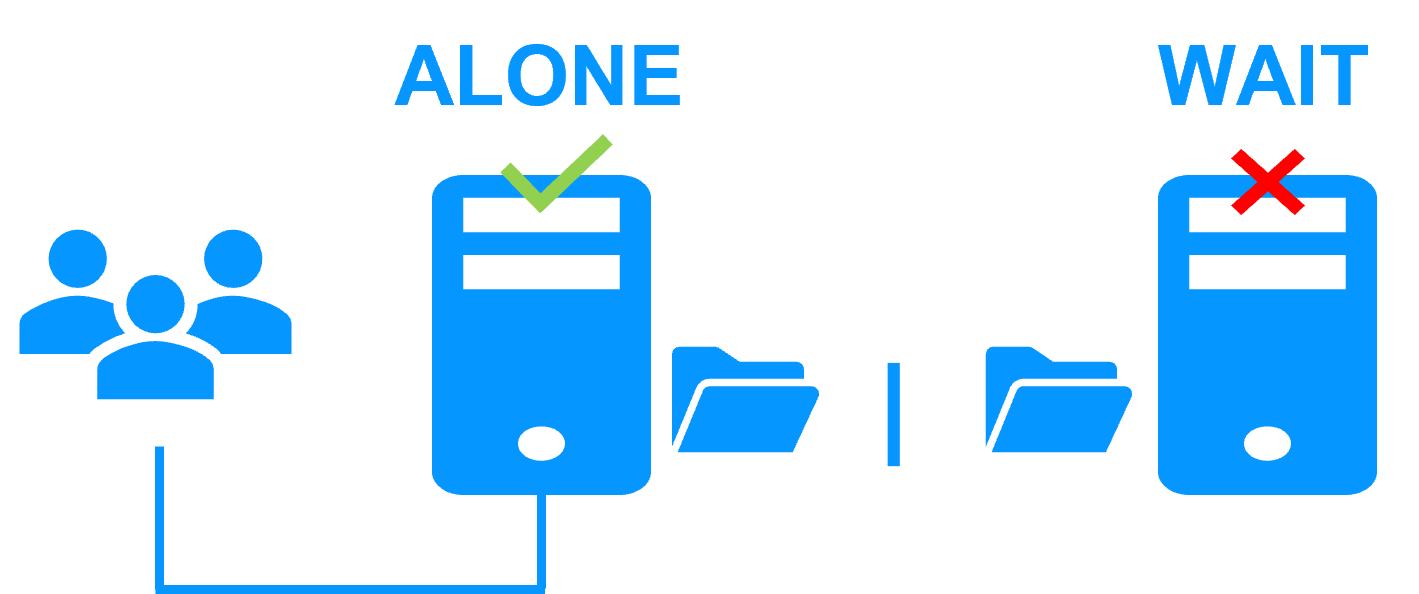
When there is a network isolation, the behavior with a split-brain checker is:
- a split-brain checker has been configured with the IP address of a witness (typically a router),
- the split-brain checker operates when a server goes from PRIM to ALONE or from SECOND to ALONE,
- in case of network isolation, before going to ALONE, both nodes test the IP address,
- the node which can access the IP address goes to ALONE, the other one goes to WAIT,
- when the isolation is repaired, the WAIT node resynchronizes its data and becomes SECOND.
Note: If the witness is down or disconnected, both nodes go to WAIT and the application is no more running. That's why you must choose a robust witness like a router.