Virtual IP (VIP) & Networking
What is a Virtual IP (VIP) and how does it differ from a physical IP?
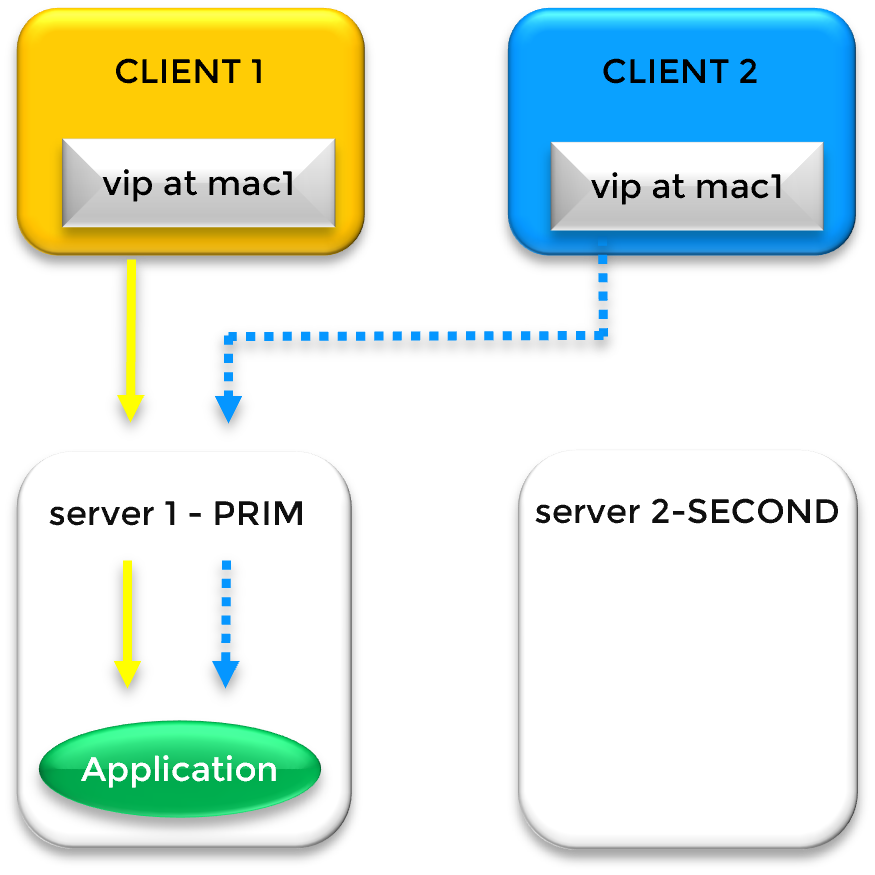
While a physical IP address is bound to a specific network interface, a Virtual IP (VIP) is a "floating" address independent of hardware. In a SafeKit cluster, the VIP acts as a persistent entry point; if the primary server fails, the VIP automatically migrates to a healthy secondary node, ensuring zero client reconfiguration.
Do I need a hardware load balancer to use a Virtual IP?
No. SafeKit High Availability software manages the Virtual IP at the software level. In same-subnet architectures, it utilizes IP aliasing and Gratuitous ARP (GARP) to redirect traffic. This eliminates the cost and complexity of external hardware load balancers or dedicated proxy servers.
What is Gratuitous ARP (GARP) and why is it used?
Gratuitous ARP (GARP) is a network broadcast that updates the ARP tables of network switches and routers. During a failover, the new primary server sends a GARP packet to announce that the Virtual IP is now mapped to its MAC address, forcing immediate traffic rerouting across the network fabric.
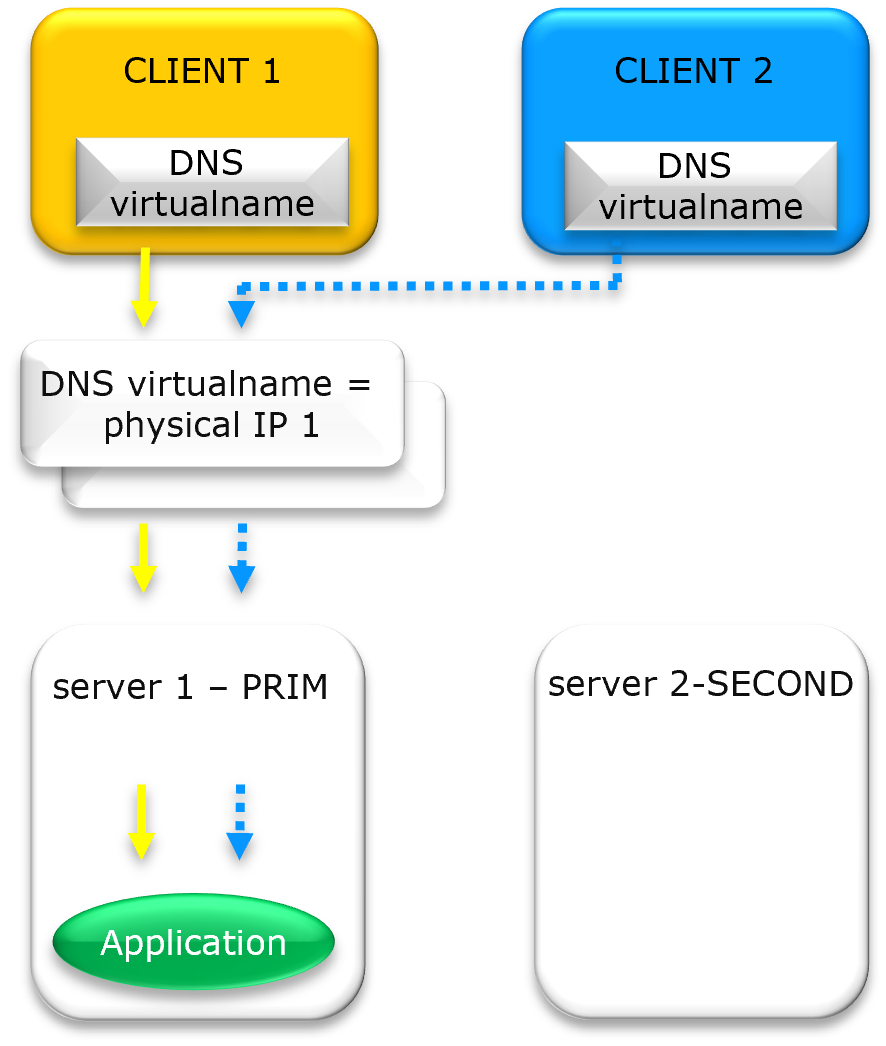
Can I associate a DNS name with a Virtual IP?
Yes. You can associate a DNS name with a VIP by creating a standard A record. The key benefit is that redirection is managed at the VIP level (via ARP or network redirection) and not at the DNS level. This ensures application transparency by avoiding delays associated with DNS propagation and TTL expiration.
Cloud & Advanced Architectures
How does a Virtual IP work in the Cloud (AWS, Azure, GCP)?
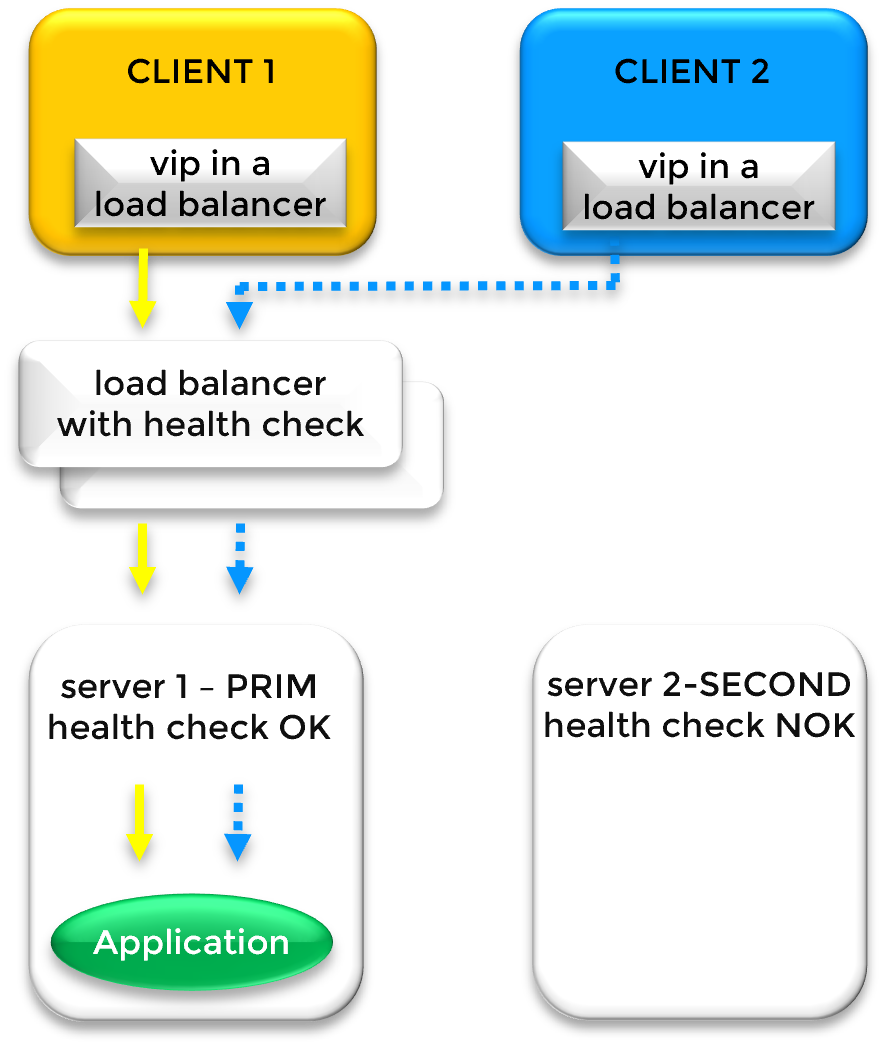
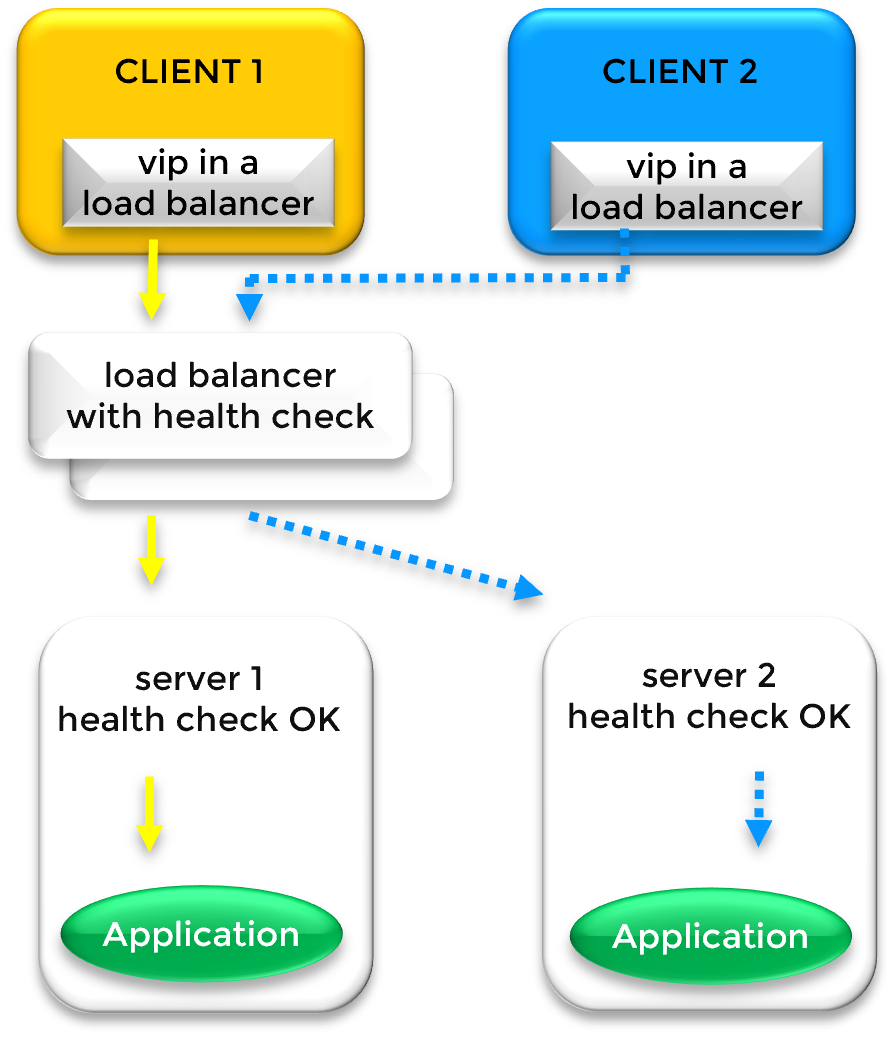
In cloud environments where Layer 2 (ARP) is restricted, SafeKit integrates with Cloud Load Balancers (AWS ELB, Azure LB, or Google GCLB). SafeKit provides a Health Check URL that the platform monitors to route traffic to the active node using SNAT/DNAT.
Is an Extended LAN better than a Load Balancer for Disaster Recovery?
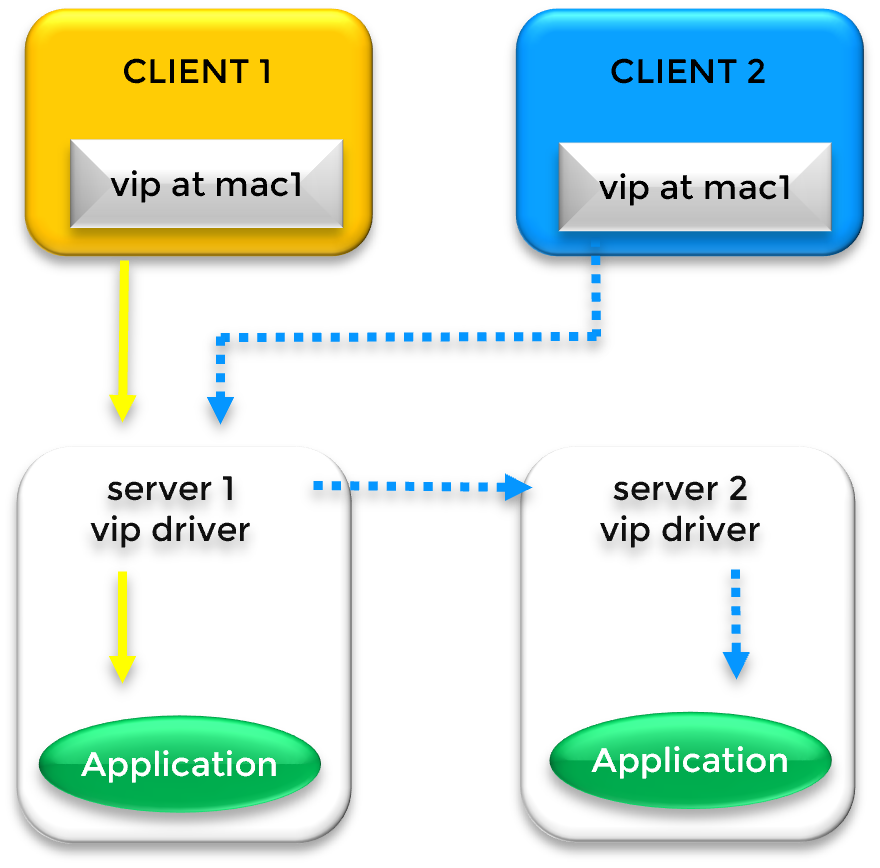
Yes. For remote datacenters, an Extended LAN (stretched VLAN) is often superior because it maintains application transparency across sites. By keeping the same Virtual IP, the application and its clients continue to communicate using the same identity, making the transition between data centers completely seamless.
What are the limitations of DNS rerouting vs. Virtual IP?
DNS rerouting is limited by TTL (Time to Live) and client-side caching, which can delay recovery for hours. A major drawback is that clients which do not re-resolve their DNS name remain stuck attempting to connect to the failed server. In contrast, a Virtual IP provides instantaneous Layer 2 failover that reroutes all traffic immediately, ensuring connectivity regardless of client-side DNS cache status.
Transparency & Security
Why is a local Virtual IP important for application transparency?
A local Virtual IP (VIP) ensures application transparency by allowing the software to bind to a persistent VIP. SafeKit handles redirection at the kernel level, keeping the application unaware of cluster failovers, unlike DNAT solutions where the binded IP changes.
Does using a Virtual IP preserve the client's original IP address?
Yes. SafeKit avoids Source Network Address Translation (SNAT). Because the VIP is local to the active server, the application receives the original Client IP, which is critical for security auditing, session persistence, and regulatory logging.