What is the SafeKit Farm NLB solution for Apache?
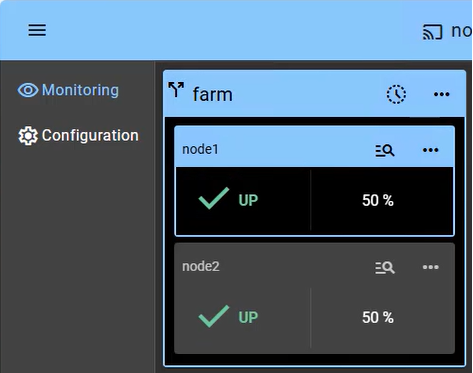
SafeKit provides network load balancing and high availability to Apache across two or more servers.
This article explains how to quickly implement a Apache cluster without hardware load balancers or specialized networking skills.
The solution works by defining a virtual IP with load balancing rules, the Apache service names, and health checkers.
SafeKit then enables network load balancing and automatic failover to ensure scalability and continuous service availability.