Aperçu
Cet article étudie les avantages et les inconvénients des techniques de réplication de données au niveau base de données, disque et fichier pour les clusters de haute disponibilité. Nous étudions le basculement sur panne, le retour après panne, la simplicité de mise en œuvre.

Les tableaux comparatifs suivants détaillent les techniques de réplication de données mises en œuvre par SafeKit, un produit logiciel de haute disponibilité.
Cluster miroir d'Evidian SafeKit avec réplication de fichiers temps réel et reprise sur panne |
|
|
Économisez avec 3 produits en 1 
|
|
|
Configuration très simple 
|
|
|
Réplication synchrone 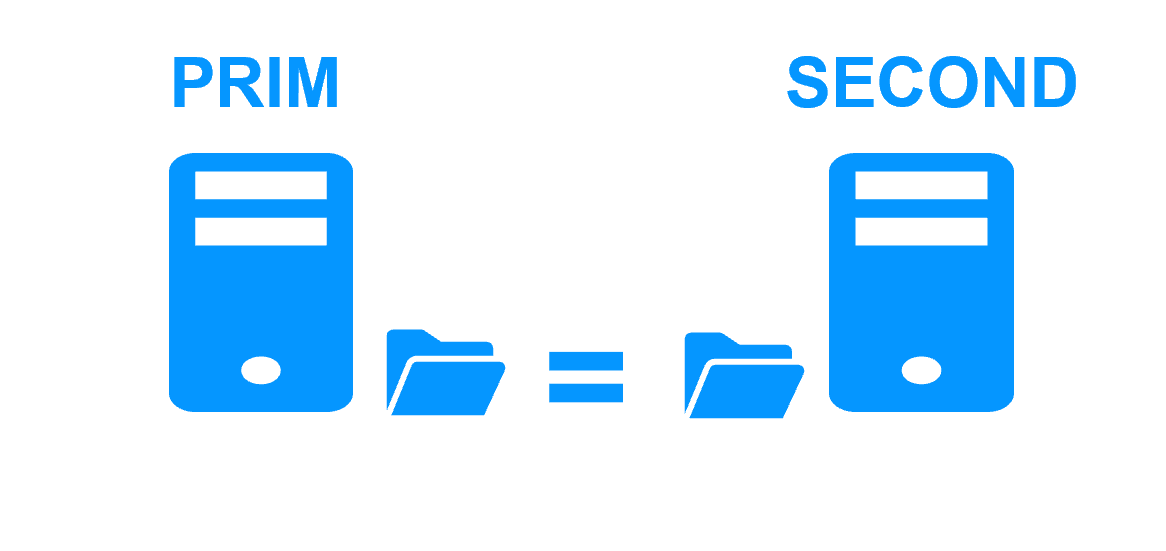
|
|
|
Retour d'un serveur tombé en panne totalement automatisé (failback) 
|
|
|
Réplication de n'importe quel type de données 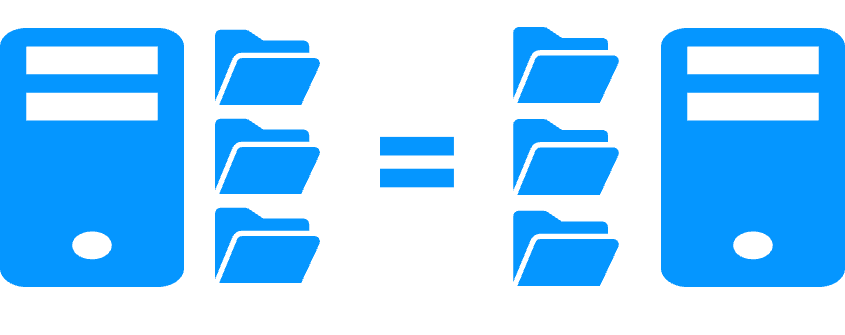
|
|
|
Réplication de fichiers vs réplication de disque 
|
|
|
Réplication de fichiers vs disque partagé 
|
|
|
Sites distants et adresse IP virtuelle 
|
|
|
Split brain et quorum En savoir plus > 
|
|
|
Cluster actif/actif 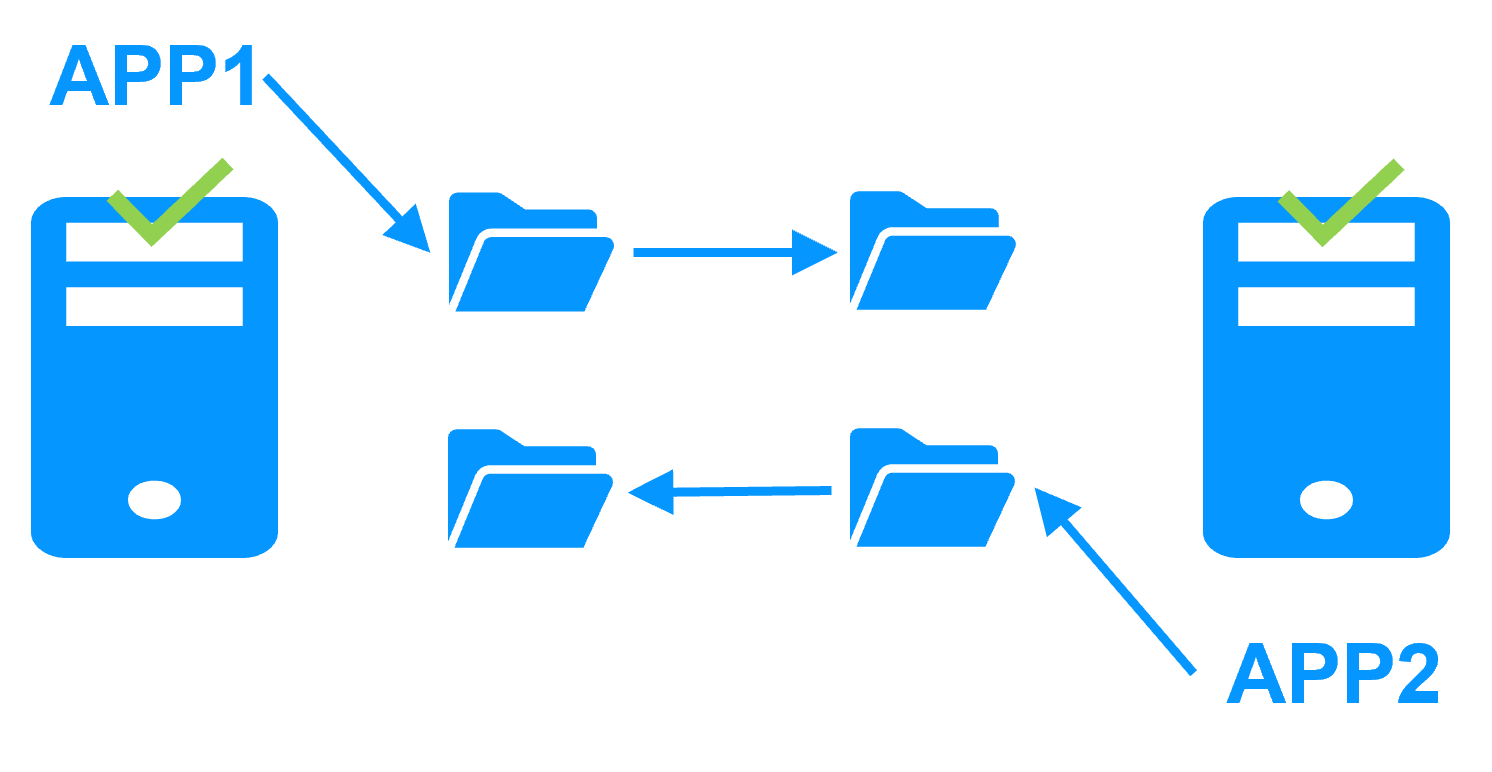
|
|
|
Solution de haute disponibilité uniforme 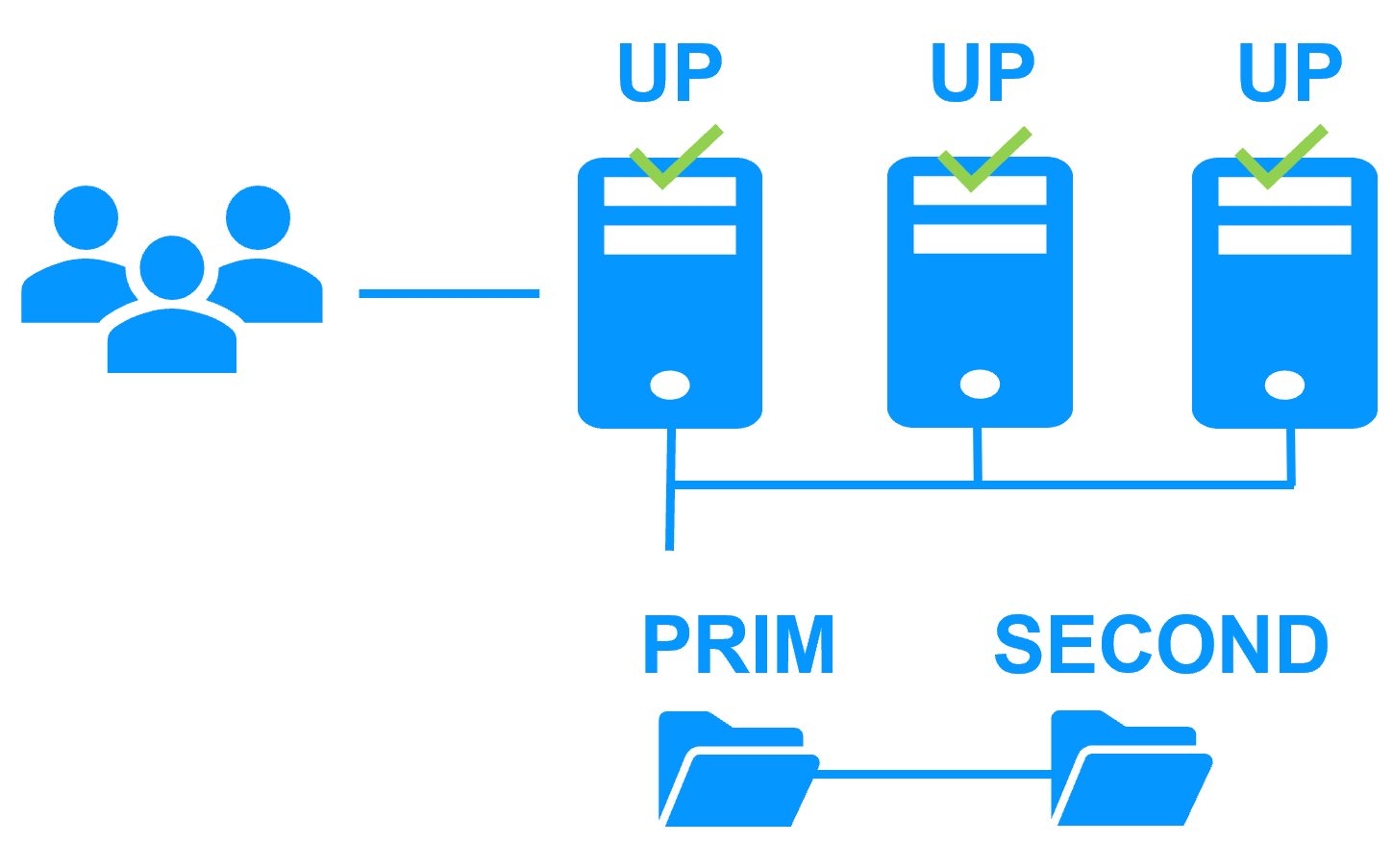
|
|
|
|
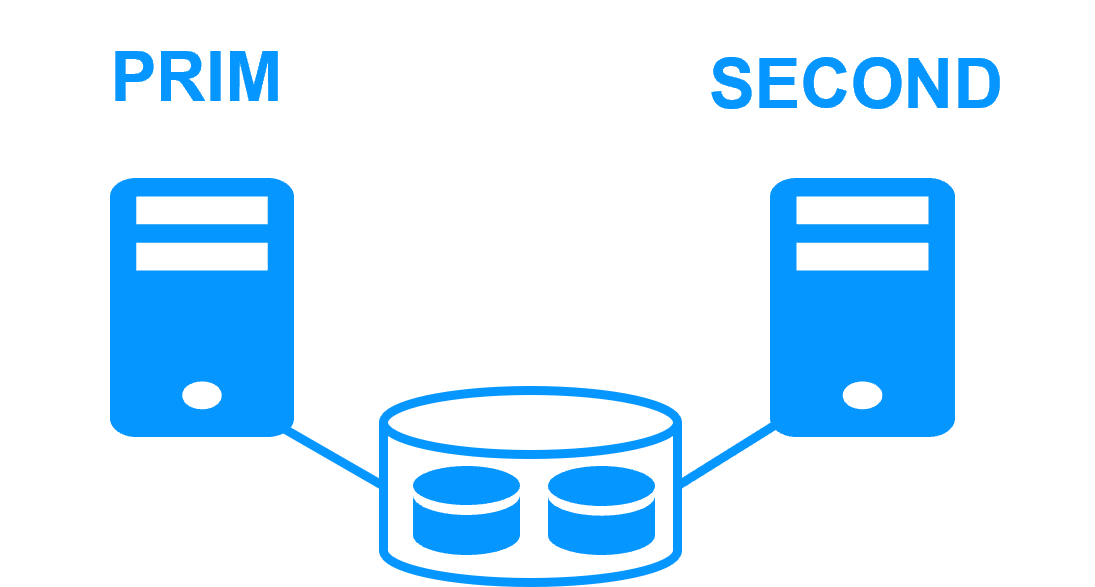


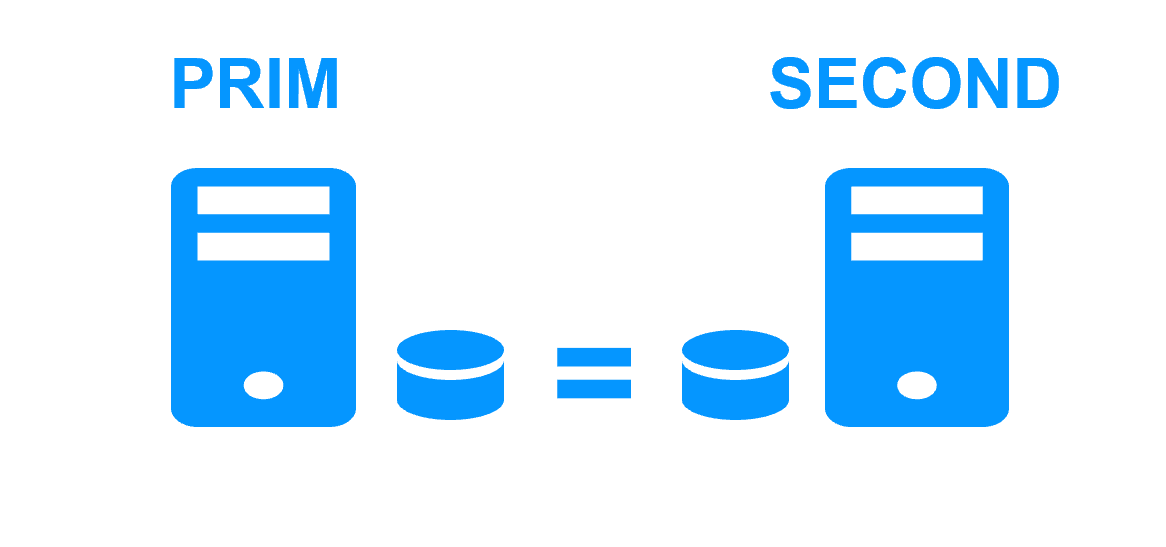

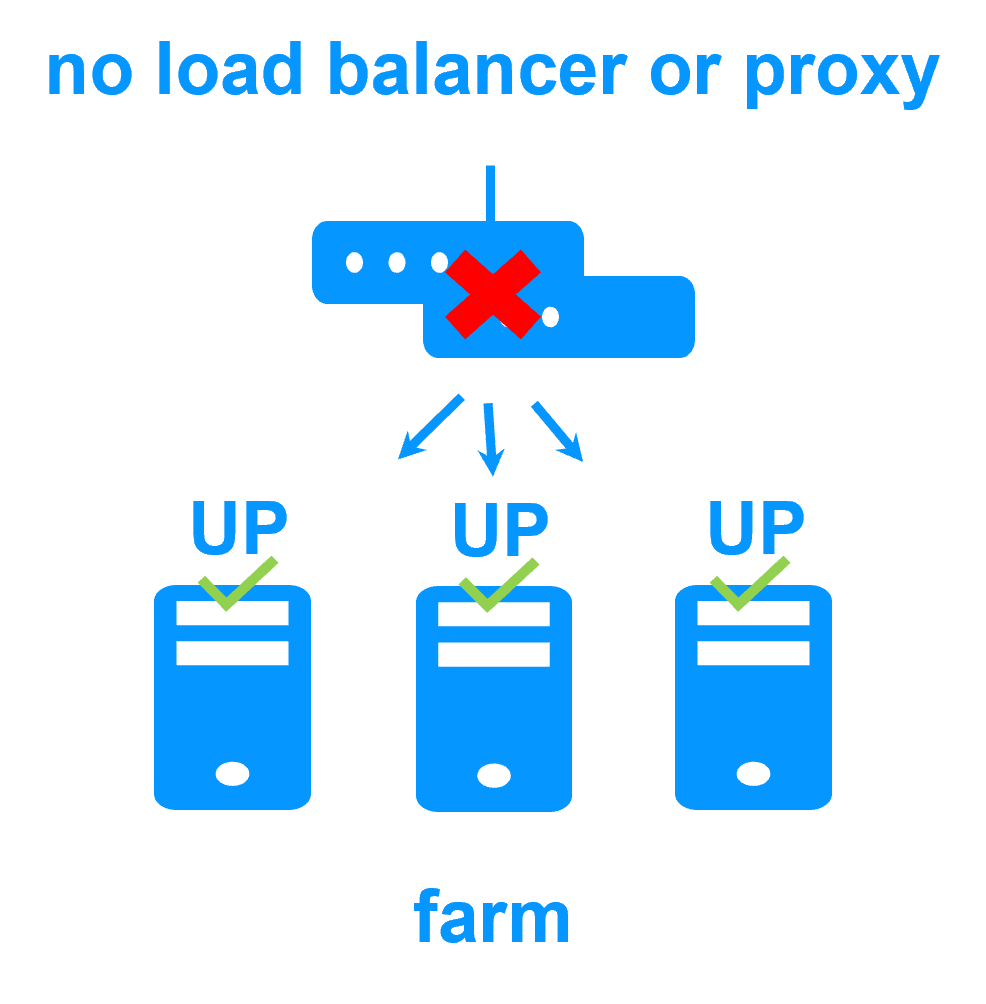
Etape 1. Réplication en temps réel
Le serveur 1 (PRIM) exécute l'application. Les utilisateurs sont connectés à une adresse IP virtuelle. Seules les modifications faites par l'application à l'intérieur des fichiers sont répliquées en continue à travers le réseau.
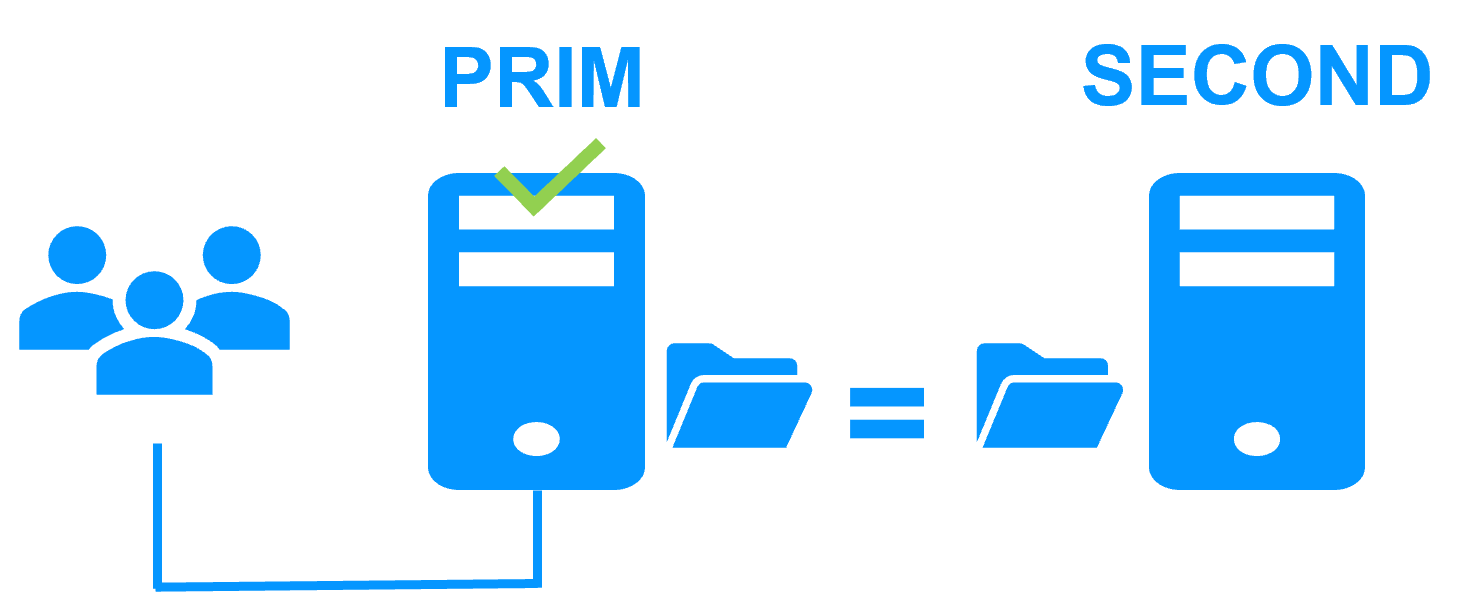
La réplication est synchrone sans perte de données en cas de panne contrairement à une réplication asynchrone.
Il vous suffit de configurer les noms des répertoires à répliquer dans SafeKit. Il n'y a pas de pré-requis sur l'organisation du disque. Les répertoires peuvent se trouver sur le disque système.
Etape 2. Basculement automatique
Lorsque le serveur 1 est défaillant, SafeKit bascule l'adresse IP virtuelle sur le serveur 2 et redémarre automatiquement l'application. L'application retrouve les fichiers répliqués à jour sur le serveur 2.
L'application poursuit son exécution sur le serveur 2 en modifiant localement ses fichiers qui ne sont plus répliqués vers le serveur 1.
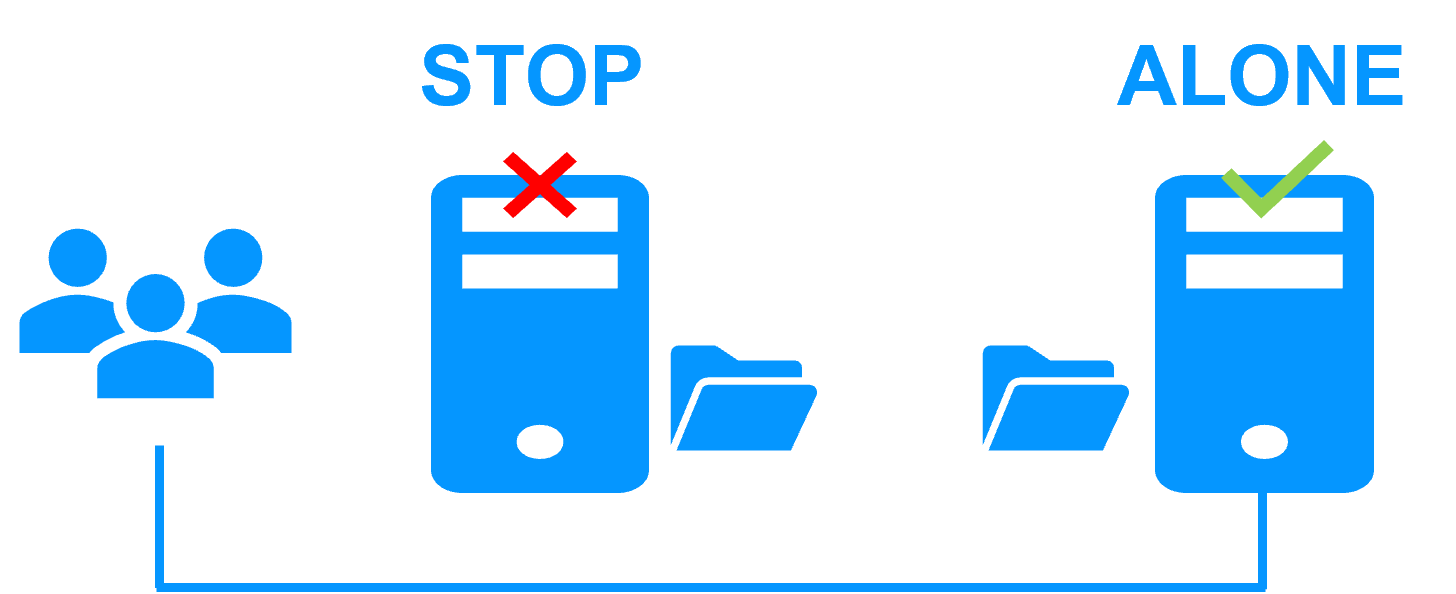
Le temps de basculement est égal au temps de détection de la panne (30 secondes par défaut) et au temps de relance de l'application.
Etape 3. Réintégration après panne
A la reprise après panne du serveur 1 (réintégration du serveur 1), SafeKit resynchronise automatiquement les fichiers de ce serveur à partir de l'autre serveur.
Seuls les fichiers modifiés sur le serveur 2 pendant l'inactivité du serveur 1 sont resynchronisés.
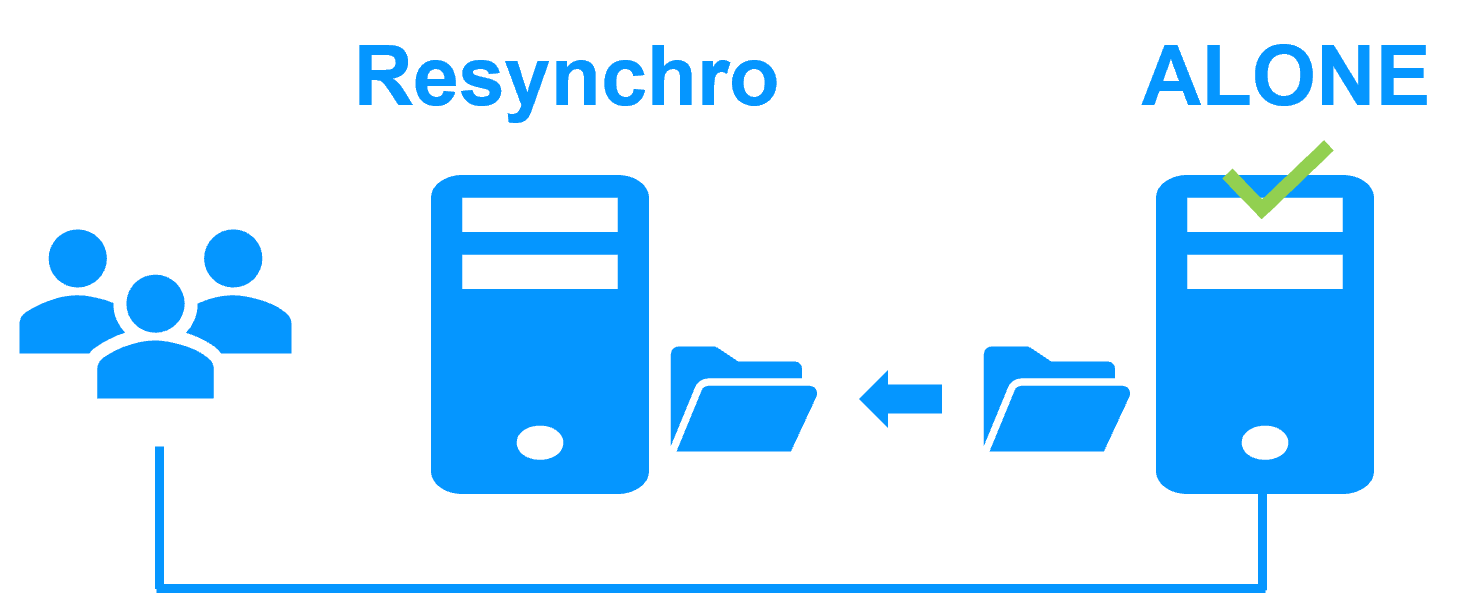
La réintégration du serveur 1 se fait sans arrêter l'exécution de l'application sur le serveur 2.
Etape 4. Retour à la normale
Après la réintégration, les fichiers sont à nouveau en mode miroir comme à l'étape 1. Le système est en haute disponibilité avec l'application qui s'exécute sur le serveur 2 et avec réplication temps réel des modifications vers le serveur 1.
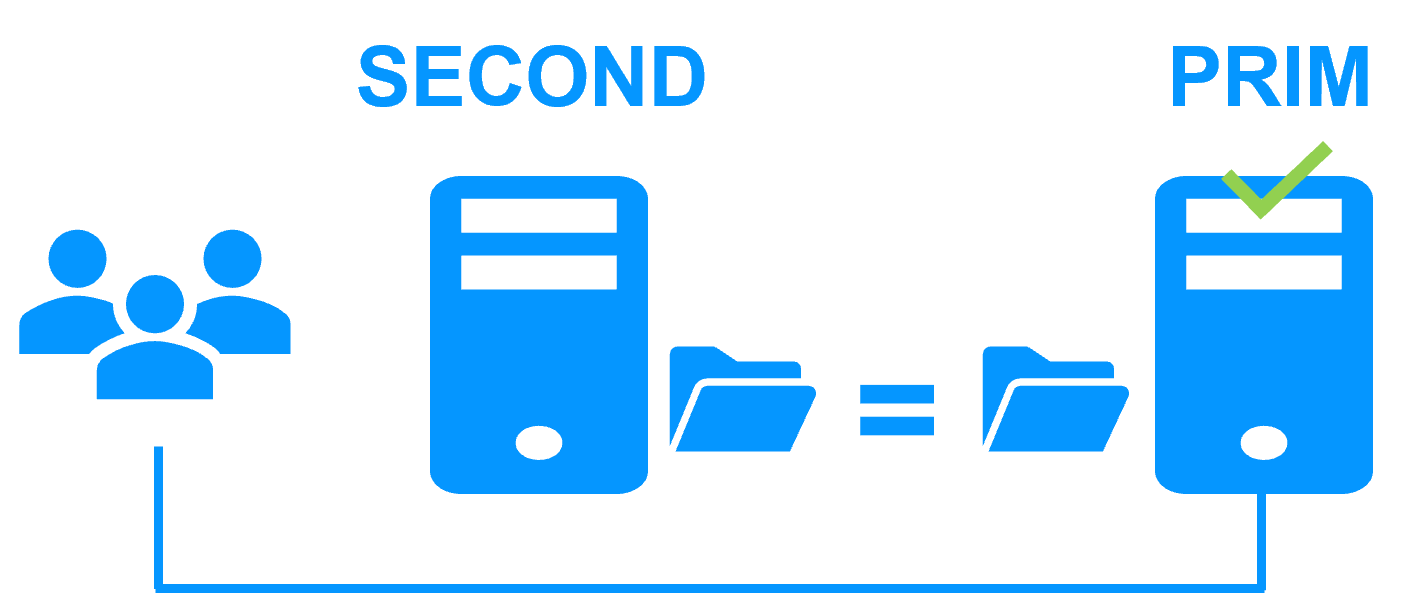
Si l'administrateur souhaite que son application s'exécute en priorité sur le serveur 1, il peut exécuter une commande de basculement, soit manuellement à un moment opportun, soit automatiquement par configuration.