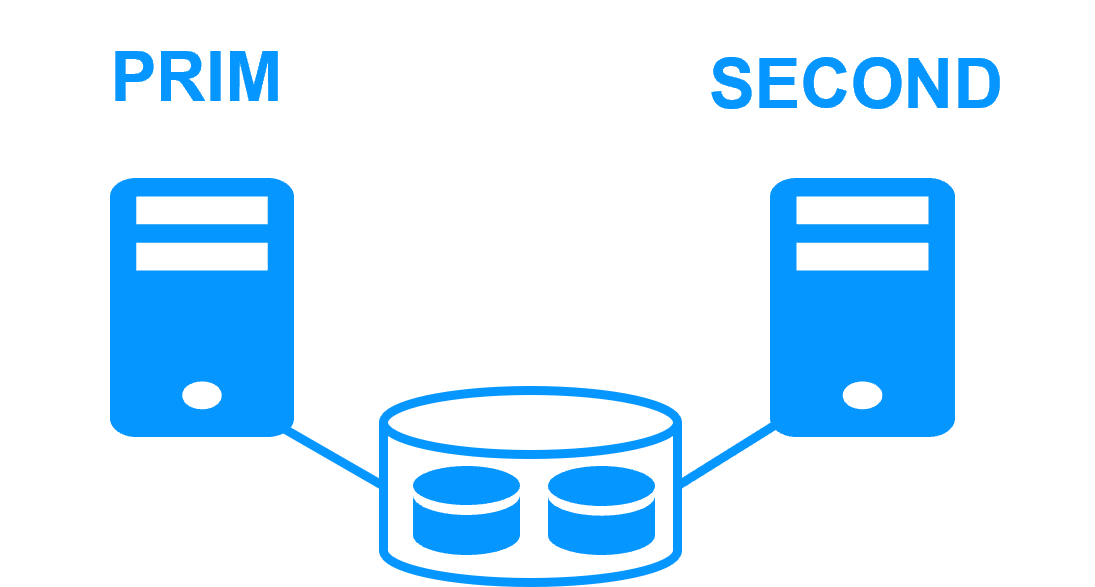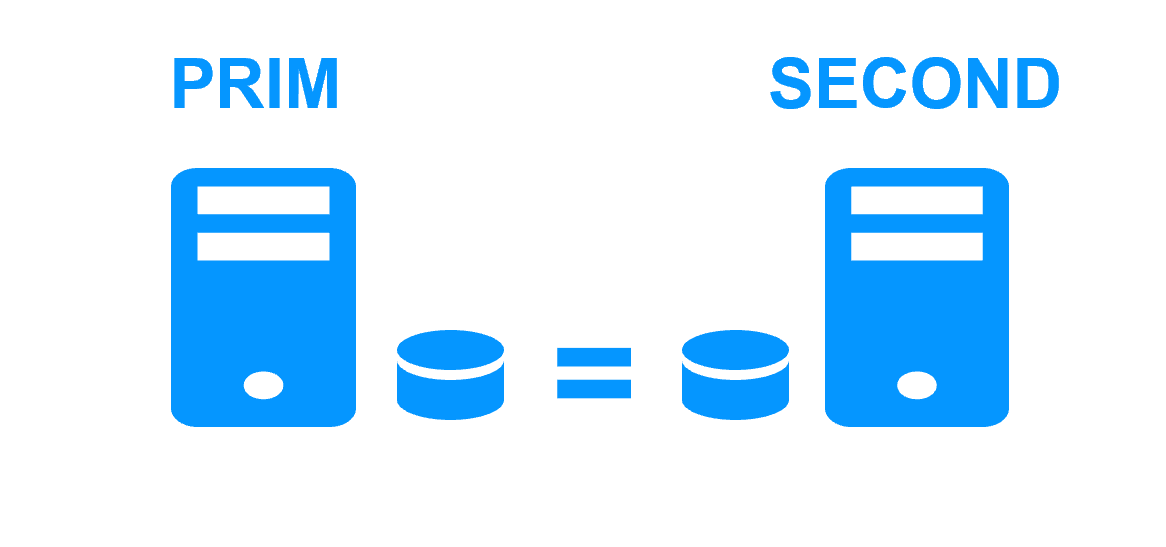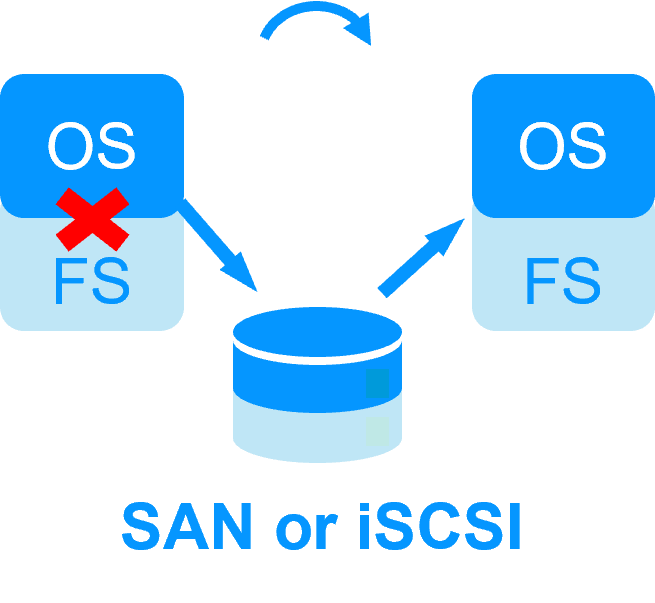
Plusieurs éléments rendent cette architecture complexe à mettre en œuvre :
- en cas de basculement, la commutation du stockage partagé nécessite des instructions de bas niveau qui dépendent du fabricant du stockage,
- la procédure de récupération du système de fichiers (FS) doit être passée avant de redémarrer l'application,
- si les deux systèmes de fichiers sur les deux nœuds accèdent au même disque en même temps, le système de fichiers complet sera corrompu,
- pour éviter un double accès, un disque de quorum doit être configuré.
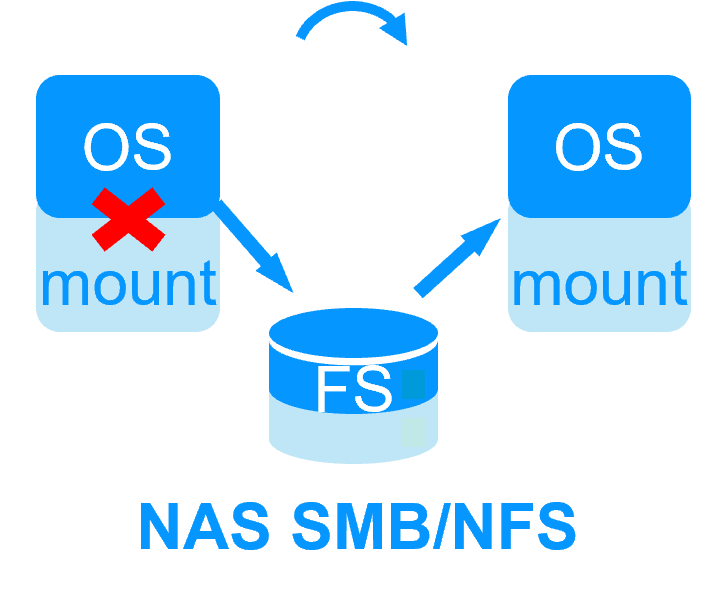
- Plusieurs éléments rendent cette architecture simple à mettre en œuvre :
- en cas de basculement, le basculement du stockage partagé consiste uniquement au remontage du système de fichiers externe,
- aucune procédure de récupération sur le système de fichiers ne doit être passée avant de redémarrer l'application,
- si les deux nœuds accèdent au même système de fichiers partagé en même temps, le système de fichiers complet ne sera pas corrompu,
- cependant, il existe toujours la possibilité qu'une double exécution de la même application corrompent ses données dans le stockage partagé lorsque les nœuds sont isolés.
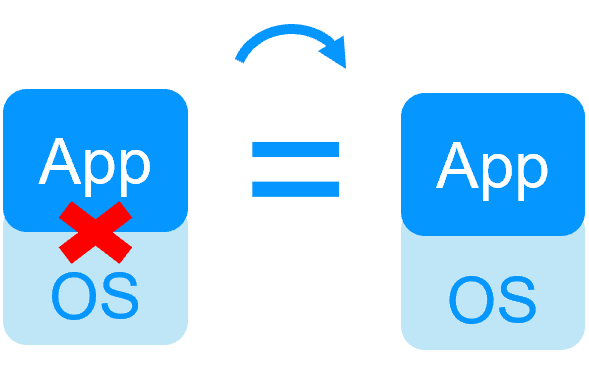
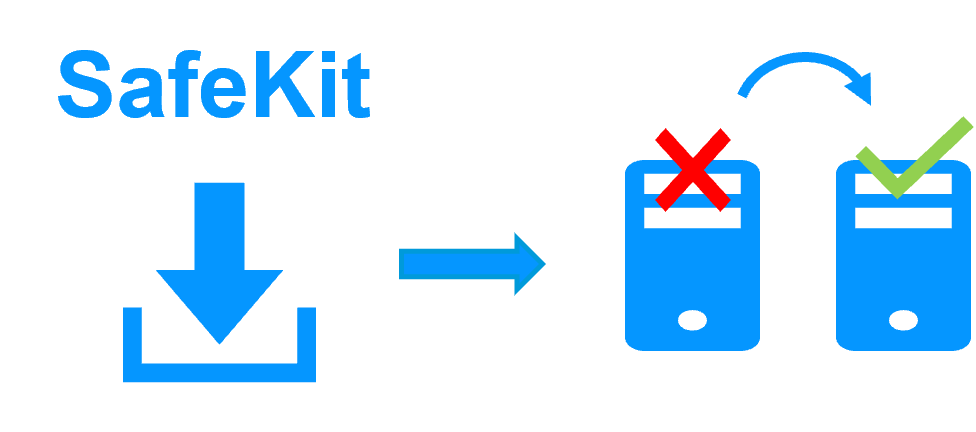
Il n'y a pas de tels problèmes avec SafeKit car sa solution de réplication et de basculement ne nécessite pas de stockage partagé.
Cependant, si SafeKit doit gérer un stockage partagé :
- utiliser un stockage partagé NAS SMB ou un stockage partagé NAS NFS,
- mettre dans les scripts de redémarrage le montage/démontage du système de fichiers externe,
- configurer le split brain checker de SafeKit pour éviter une double exécution de la même application accédant au stockage partagé lorsque les nœuds sont isolés.
Etape 1. Réplication en temps réel
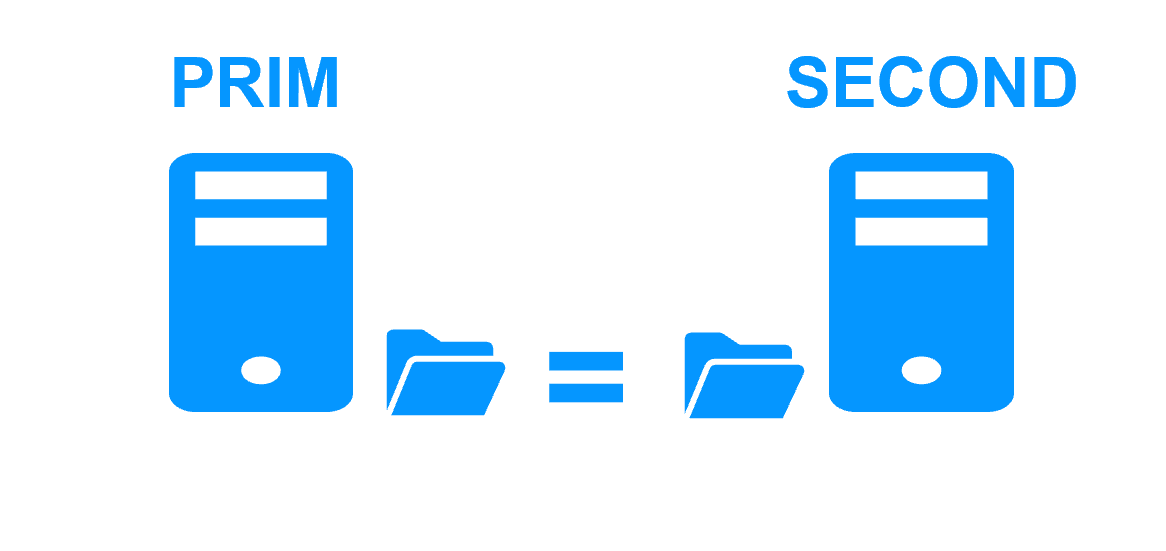
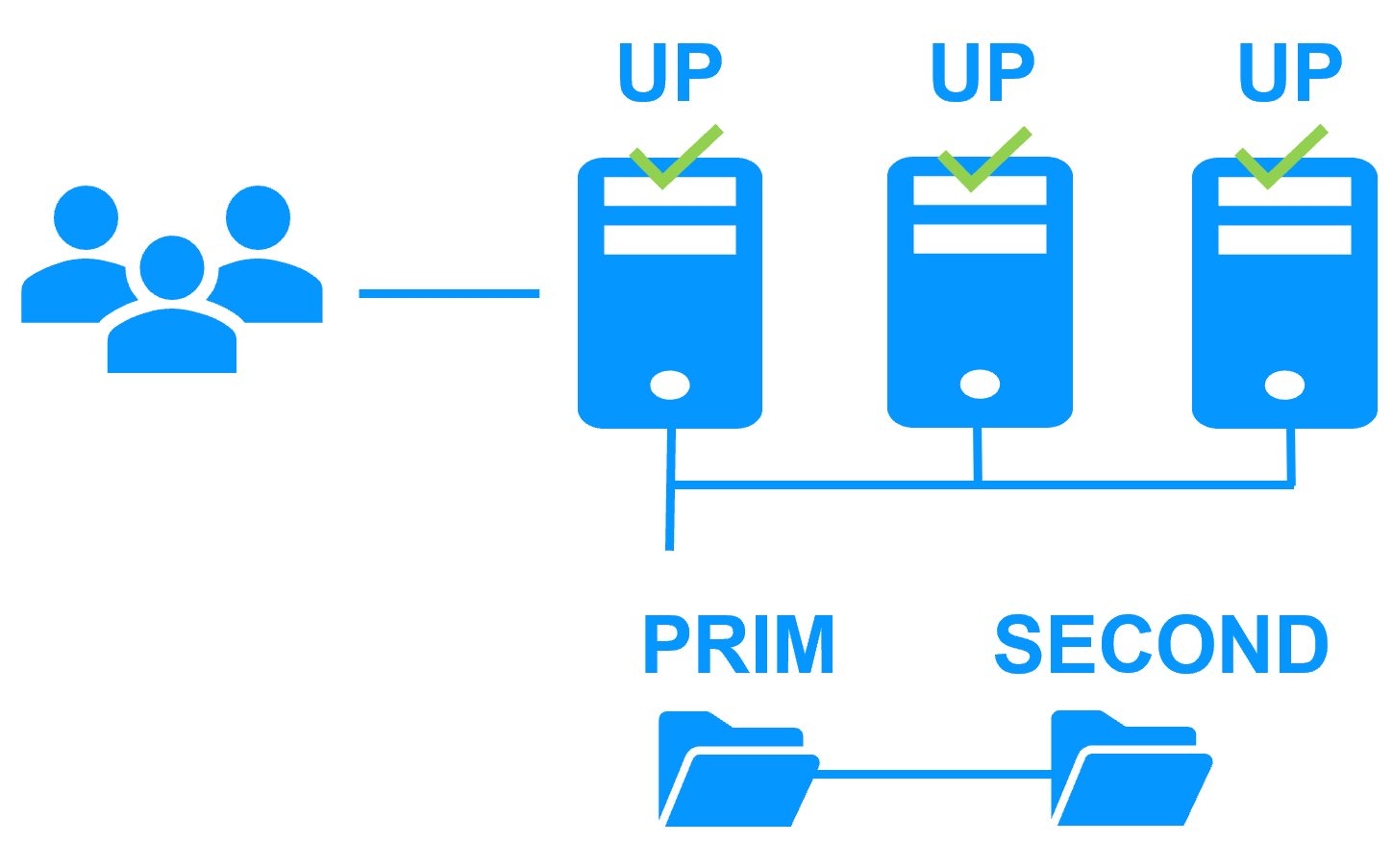
Le serveur 1 (PRIM) exécute l'application Windows or Linux. Les utilisateurs sont connectés à une adresse IP virtuelle. Seules les modifications faites par l'application à l'intérieur des fichiers sont répliquées en continue à travers le réseau.
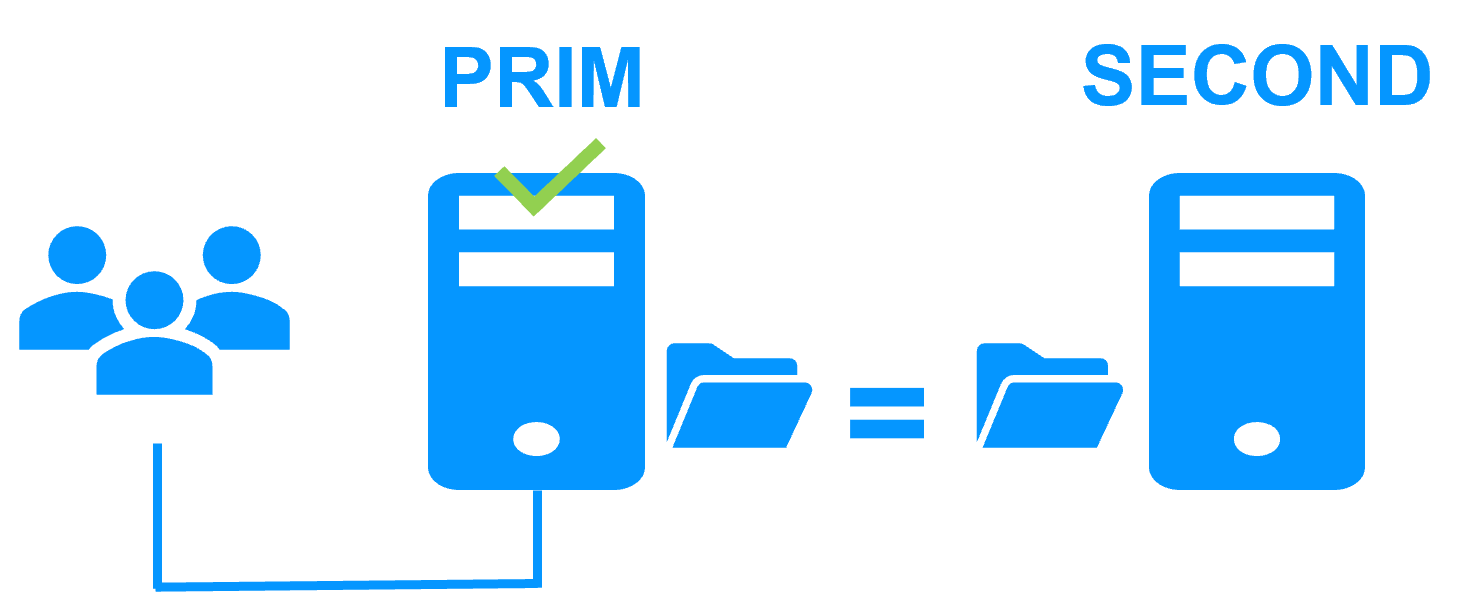
La réplication est synchrone sans perte de données en cas de panne contrairement à une réplication asynchrone.
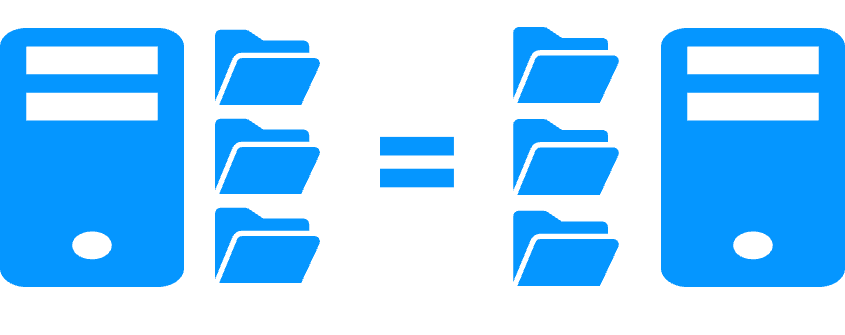
Il vous suffit de configurer les noms des répertoires à répliquer dans SafeKit. Il n'y a pas de pré-requis sur l'organisation du disque. Les répertoires peuvent se trouver sur le disque système.
Etape 2. Basculement automatique
Lorsque le serveur 1 est défaillant, SafeKit bascule l'adresse IP virtuelle sur le serveur 2 et redémarre automatiquement l'application Windows or Linux. L'application retrouve les fichiers répliqués à jour sur le serveur 2.
L'application poursuit son exécution sur le serveur 2 en modifiant localement ses fichiers qui ne sont plus répliqués vers le serveur 1.
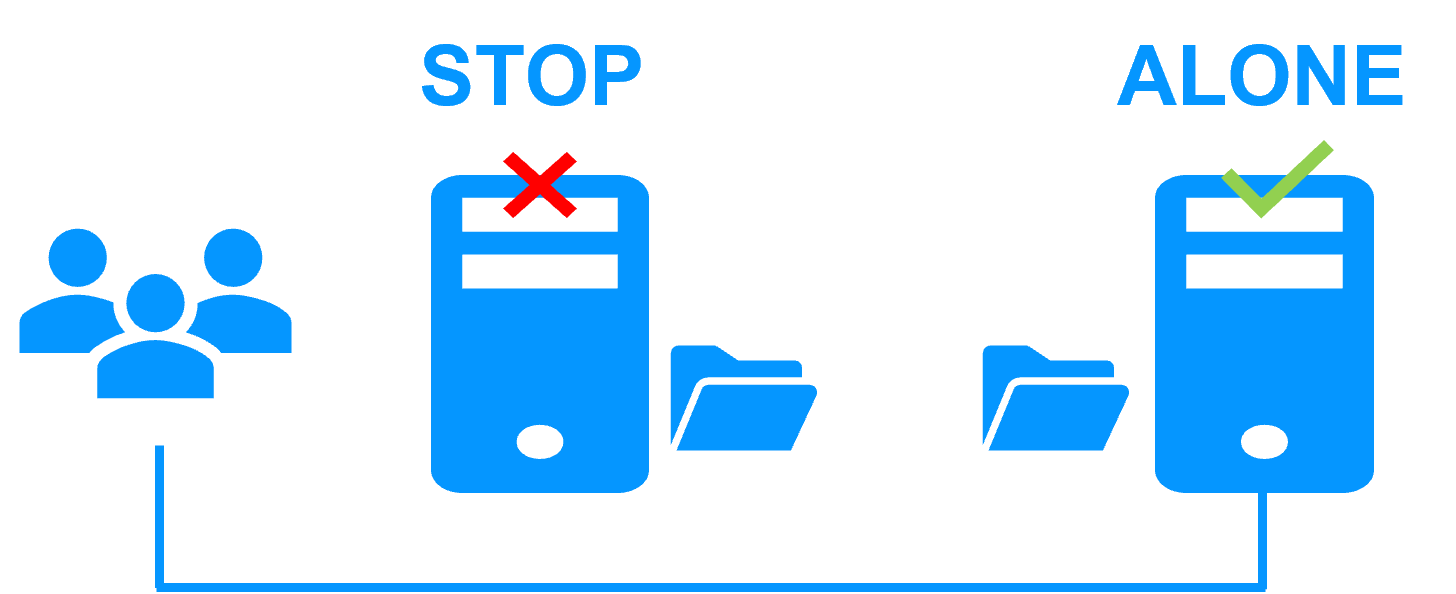
Le temps de basculement est égal au temps de détection de la panne (30 secondes par défaut) et au temps de relance de l'application.
Etape 3. Réintégration après panne
A la reprise après panne du serveur 1 (réintégration du serveur 1), SafeKit resynchronise automatiquement les fichiers de ce serveur à partir de l'autre serveur.
Seuls les fichiers modifiés sur le serveur 2 pendant l'inactivité du serveur 1 sont resynchronisés.
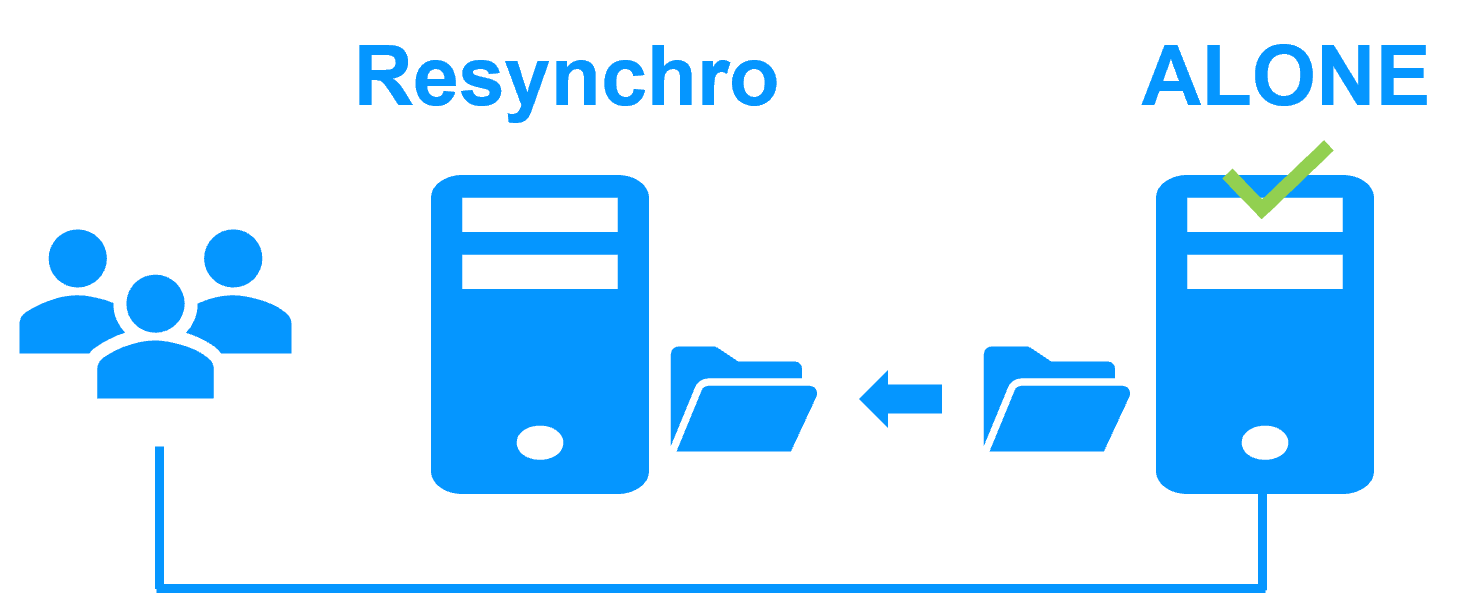
La réintégration du serveur 1 se fait sans arrêter l'exécution de l'application Windows or Linux sur le serveur 2.
Etape 4. Retour à la normale
Après la réintégration, les fichiers sont à nouveau en mode miroir comme à l'étape 1. Le système est en haute disponibilité avec l'application Windows or Linux qui s'exécute sur le serveur 2 et avec réplication temps réel des modifications vers le serveur 1.
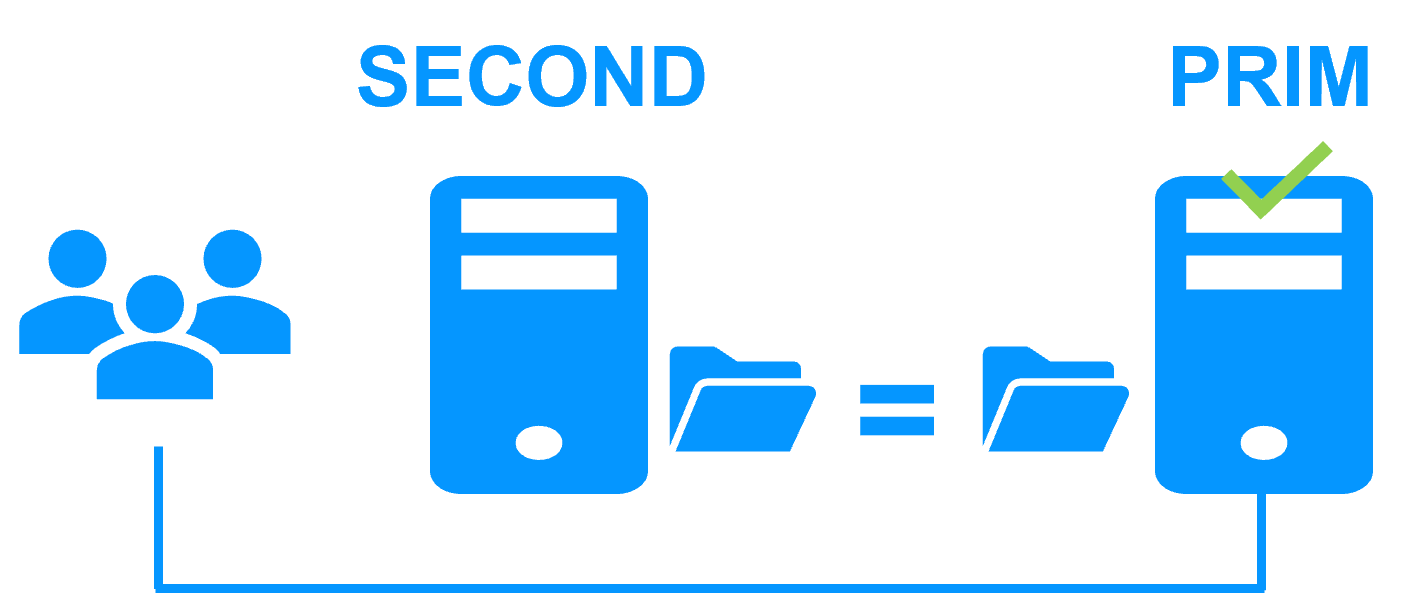
Si l'administrateur souhaite que son application s'exécute en priorité sur le serveur 1, il peut exécuter une commande de basculement, soit manuellement à un moment opportun, soit automatiquement par configuration.
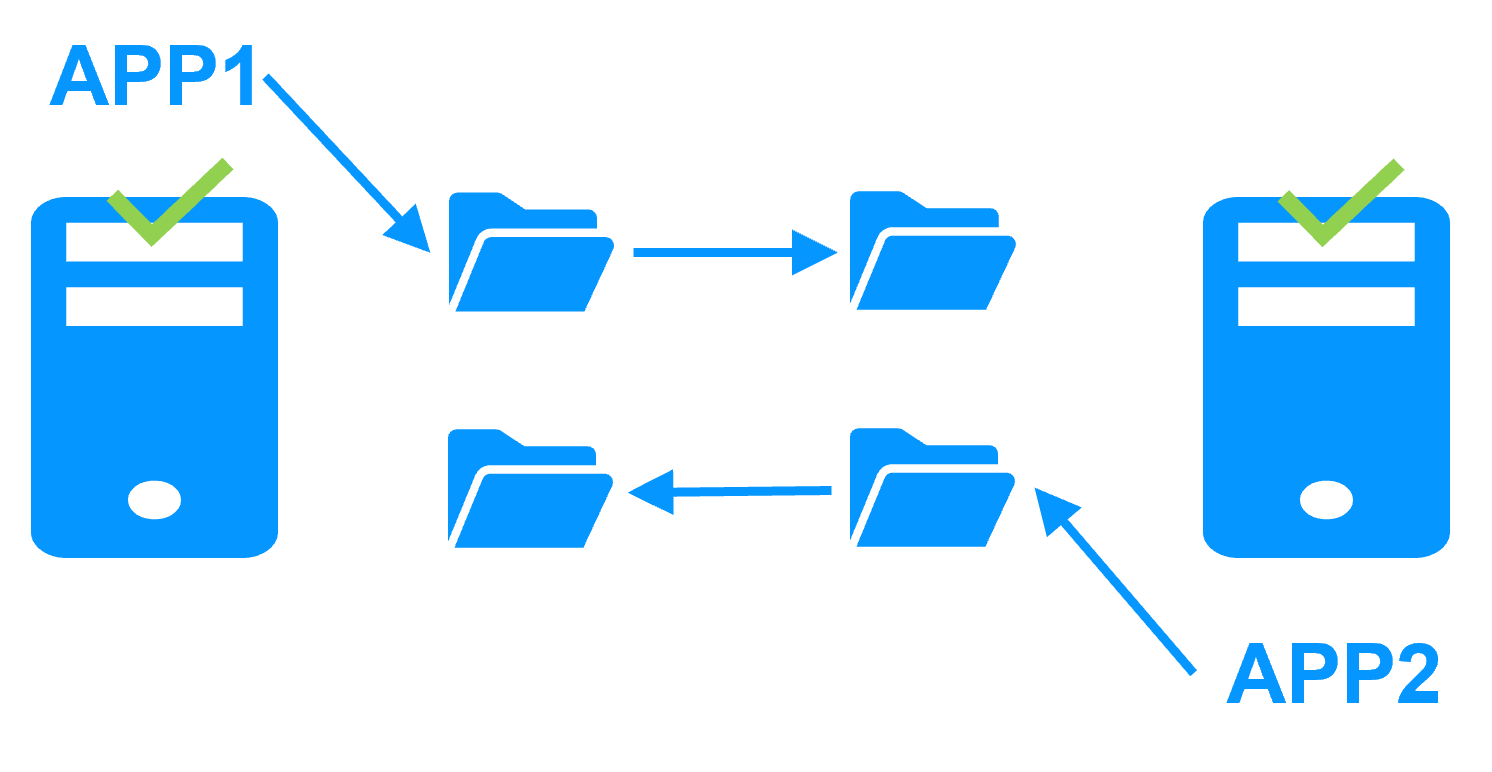
Redondance au niveau de l'application
Dans ce type de solution, seules les données applicatives sont répliquées. Et seule l'application est redémarrée en cas de panne.
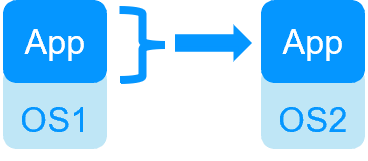
Avec cette solution, des scripts de redémarrage doivent être écrits pour redémarrer l'application.
Nous livrons des modules applicatifs pour mettre en œuvre la redondance au niveau applicatif (comme le module mirror fourni dans l'essai gratuit ci-dessous). Ils sont préconfigurés pour des applications et des bases de données bien connues. Vous pouvez les personnaliser avec vos propres services, données à répliquer, checkers d'application. Et vous pouvez combiner les modules applicatifs pour construire des architectures avancées à plusieurs niveaux.
Cette solution est indépendante de la plate-forme et fonctionne avec des applications à l'intérieur de machines physiques, de machines virtuelles, dans le Cloud. Tout hyperviseur est supporté (VMware, Hyper-V...).
Redondance au niveau de machine virtuelle
Dans ce type de solution, la machine virtuelle (VM) complète est répliquée (Application + OS). Et la machine virtuelle complète est redémarrée en cas de panne.
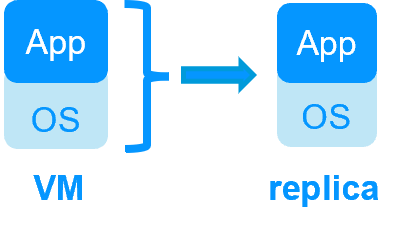
L'avantage est qu'il n'y a pas de scripts de redémarrage à écrire par application et pas d'adresse IP virtuelle à définir. Si vous ne savez pas comment fonctionne l'application, c'est la meilleure solution.
Cette solution fonctionne avec Windows/Hyper-V et Linux/KVM mais pas avec VMware. Il s'agit d'une solution active/active avec plusieurs machines virtuelles répliquées et redémarrées entre deux nœuds.
- Solution pour une nouvelle application (pas de script de redémarrage à écrire) : Windows/Hyper-V, Linux/KVM
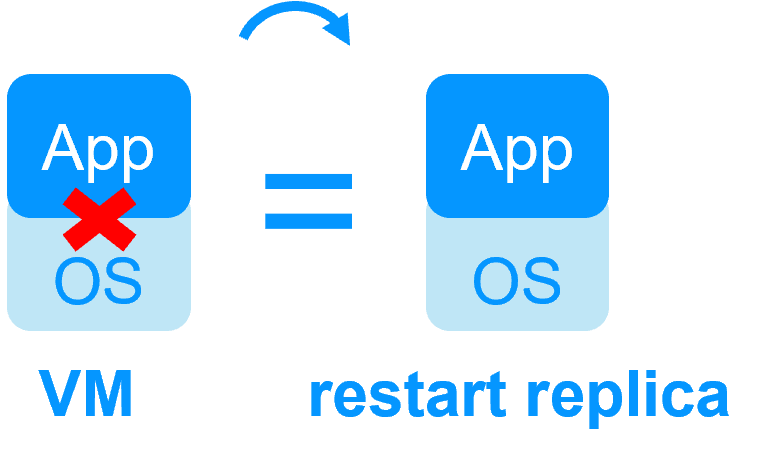
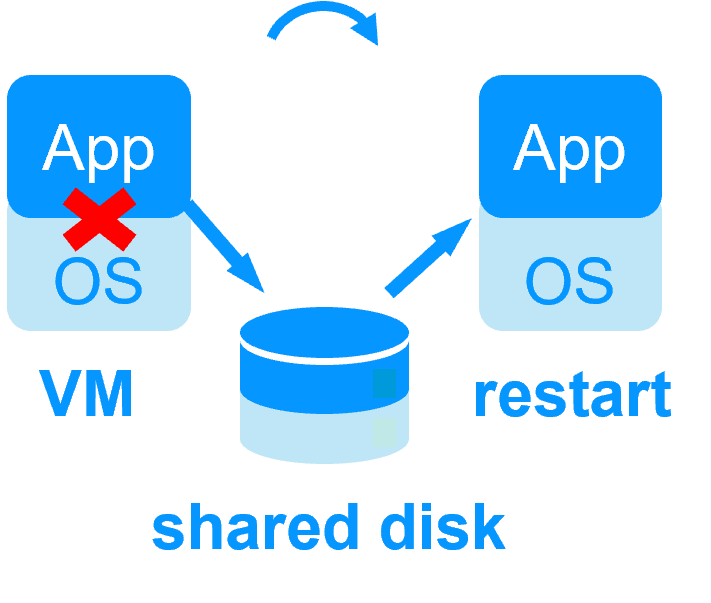
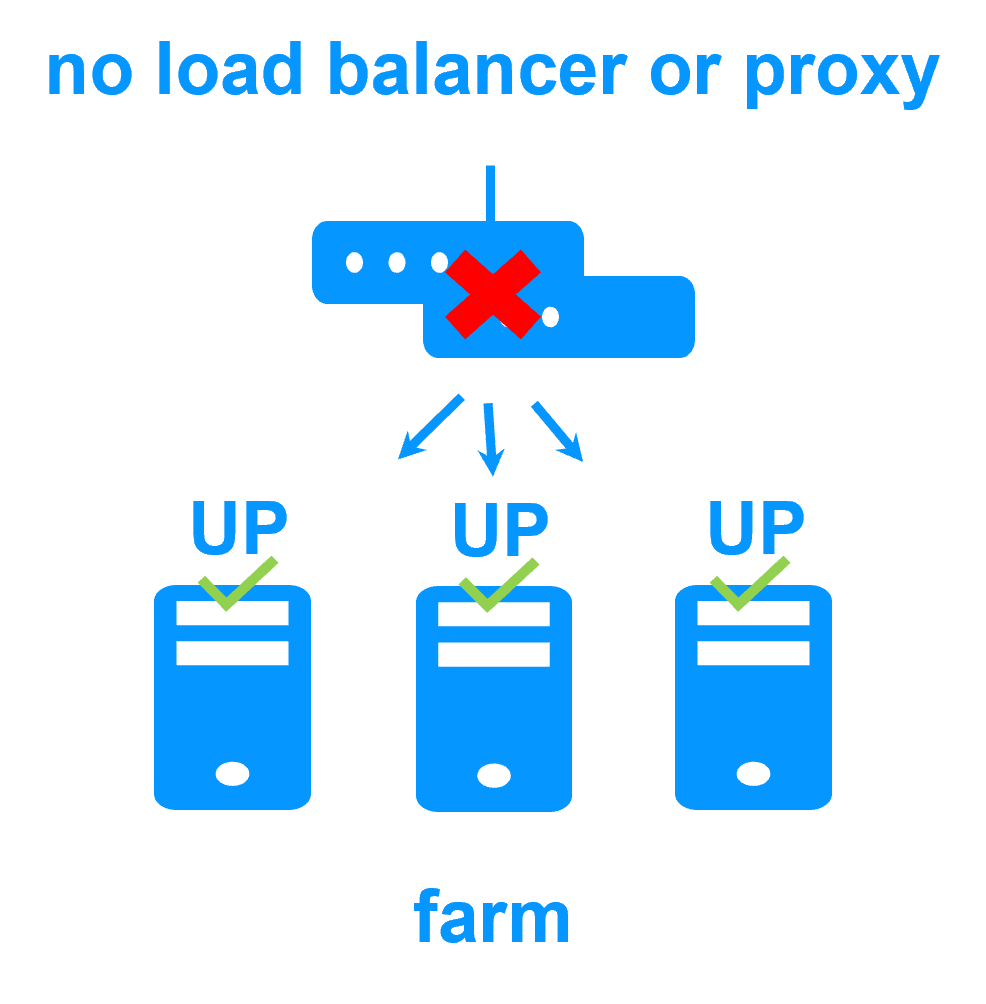
 Pas de disque partagé -
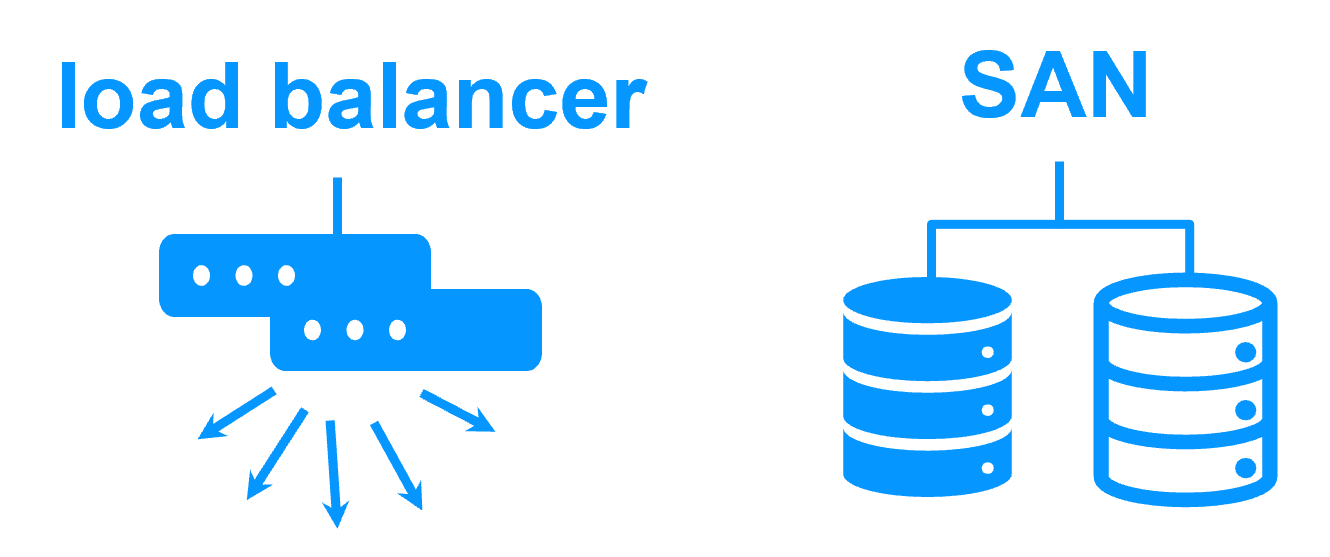
Pas de disque partagé -  Disque partagé et baie de disques externe spécifique
Disque partagé et baie de disques externe spécifique