Comment fonctionne une adresse IP virtuelle (VIP) dans un cluster à haute disponibilité ?
SafeKit VIP vs. Redirection DNS : Basculement automatique pour Windows et Linux
Qu'est-ce qu'une adresse IP virtuelle dans un cluster de haute disponibilité ?
Définition : Une adresse IP virtuelle (VIP) est une adresse réseau flottante utilisée dans les clusters de haute disponibilité pour garantir un accès continu aux applications. Contrairement aux adresses IP standards, une VIP n'est pas liée à une interface matérielle physique spécifique, mais bascule entre les nœuds du cluster pour maintenir un point d'entrée unique et persistant pour les clients.
Aucun matériel requis : SafeKit gère la VIP au niveau logiciel via l'ARP gratuit (GARP), éliminant ainsi le besoin de répartiteurs de charge (load balancers) externes dans les environnements de même sous-réseau.
Transparence applicative : En se liant à une VIP locale, les applications restent "inconscientes" des événements de basculement (failover), préservant ainsi les adresses IP sources des clients et les configurations de sécurité existantes.
Reprise après sinistre : L'utilisation d'un LAN étendu (Extended LAN) permet d'utiliser la même VIP sur des centres de données distants, simplifiant le basculement de site à site par rapport au routage DNS complexe et aux délais de mise en cache TTL.
Implémentation de l'IP virtuelle dans SafeKit
Clusters Mirror : Utilise une IP flottante active uniquement sur le serveur primaire pour faciliter la réplication en temps réel et le basculement (failover).
Clusters Farm : Permet la répartition de charge réseau (load balancing) en maintenant la VIP active sur tous les nœuds simultanément.
Avantage clé : En utilisant l'ARP gratuit (Gratuitous ARP) ou la reprise d'adresse MAC (MAC Address Takeover), la VIP permet un basculement applicatif transparent sans reconfiguration manuelle des clients, garantissant ainsi une continuité d'activité 24/7.
Cloud et multi-sous-réseaux : Gestion via les tests de santé (health checks) des répartiteurs de charge externes (AWS, Azure, GCP) pour rediriger le trafic entre différents sous-réseaux.
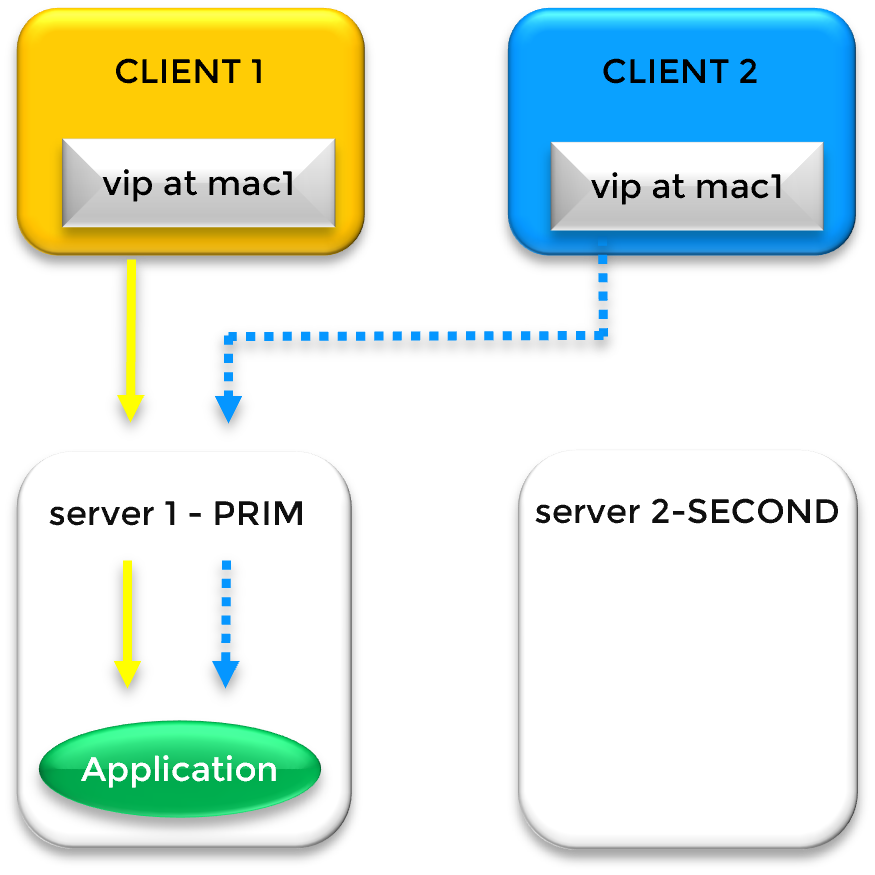
Fonctionnement d'une adresse IP virtuelle (VIP) lors d'un basculement sur le même sous-réseau (Cluster Mirror)
Basculement automatique et reroutage réseau dans un sous-réseau local
Pour les organisations exigeant une continuité d'activité sans couture au sein d'une infrastructure locale, la solution SafeKit Software-Defined High Availability pour les clusters en réseau local offre une solution robuste et automatisée pour la gestion des adresses IP virtuelles et le basculement applicatif en temps réel.
Cluster miroir local : Basculement transparent à 2 nœuds Windows ou Linux
Aliasing VIP SafeKit et mapping d'adresse MAC
Dans un cluster miroir SafeKit standard où les deux nœuds résident dans le même sous-réseau local, la haute disponibilité est assurée par une IP virtuelle (VIP) définie par logiciel. Contrairement aux solutions matérielles, SafeKit gère cette VIP directement dans la pile réseau du système d'exploitation. Cette VIP agit comme un point d'entrée logique persistant pour les clients, superposé aux adresses IP physiques uniques du Serveur 1 et du Serveur 2 via l'aliasing IP.
Aliasing IP avancé et support de VIP multiples par SafeKit
L'un des principaux avantages de la solution SafeKit réside dans sa flexibilité à gérer les identités réseau. La VIP est une troisième adresse IP qui « flotte » entre les nœuds. Notamment, SafeKit est capable de gérer plusieurs adresses IP virtuelles au sein d'un même cluster. Celles-ci peuvent être assignées à la même carte Ethernet principale ou réparties sur différentes cartes physiques, permettant des configurations complexes où différents services sont liés à des identités virtuelles spécifiques.
Le mécanisme de basculement : Gratuitous ARP (GARP)
SafeKit garantit une intervention manuelle nulle lors d'une panne matérielle. En fonctionnement normal, la VIP est mappée à l'adresse MAC du Serveur 1 (mac1). Si SafeKit détecte une défaillance du heartbeat (battement de cœur) sur le Serveur 1, il exécute une récupération en deux étapes :
Récupération applicative : SafeKit redémarre automatiquement les services applicatifs critiques sur le Serveur 2.
Reroutage réseau : SafeKit diffuse instantanément un message Gratuitous ARP (GARP). Cela force la mise à jour des caches ARP de tous les commutateurs réseau et des clients connectés, remappant la VIP sur l'adresse MAC du Serveur 2 (mac2).
Centres de données distants et VLAN étendus
Bien qu'il soit généralement utilisé pour les clusters locaux, l'algorithme de même sous-réseau de SafeKit est le choix privilégié pour la reprise après sinistre (DR) entre des sites distants connectés via un LAN étendu ou un VLAN étiré (stretched VLAN). Cette architecture « étirée » vous permet de maintenir un seul sous-réseau sur des distances géographiques, simplifiant considérablement votre topologie réseau et évitant la lourdeur des protocoles de routage complexes.
⚠️ Note : Le reroutage de niveau 2 (Layer 2) via Gratuitous ARP est la solution la plus transparente pour les applications. Contrairement au reroutage de niveau 3 (Layer 3) avec un équilibreur de charge (Load Balancer), il évite la translation d'IP source/destination (SNAT/DNAT). L'application reçoit le trafic directement avec l'IP d'origine du client, et l'IP virtuelle est configurée localement. De nombreuses applications préfèrent voir la VIP localement et recevoir directement l'IP d'origine du client. Sans cette transparence, elles pourraient ne pas fonctionner comme prévu en raison de translations réseau complexes.
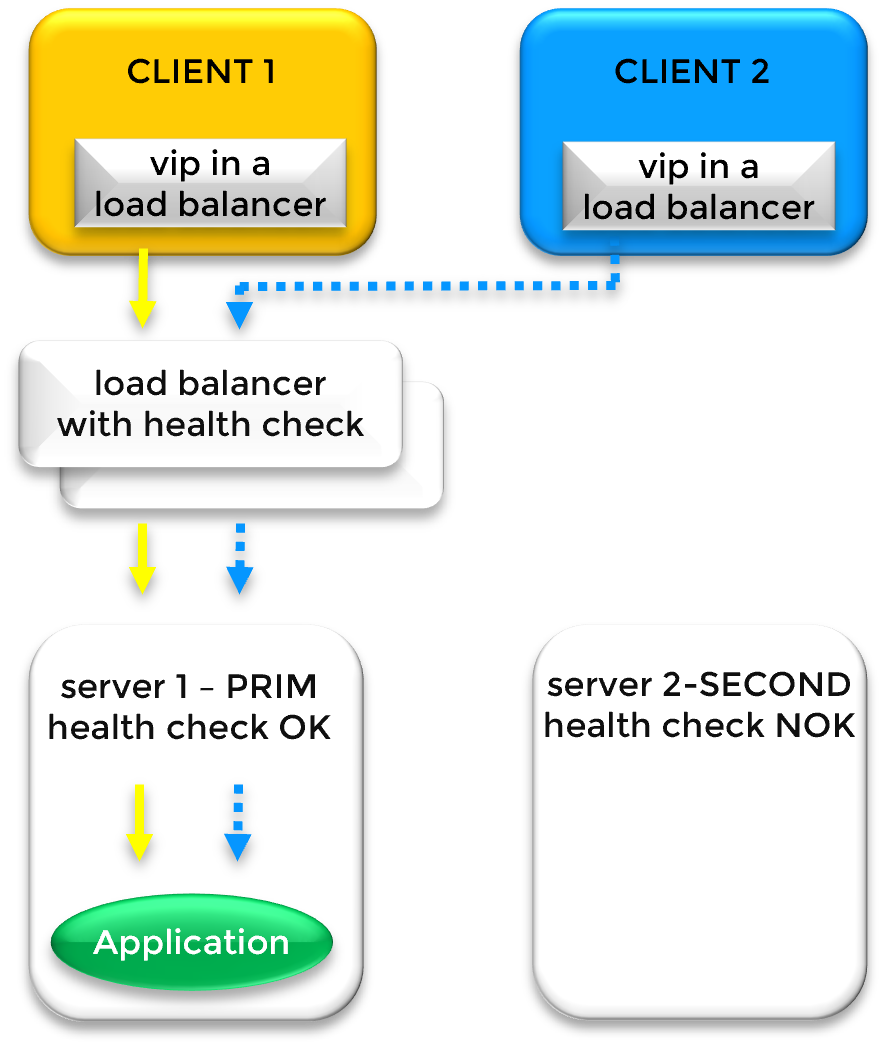
Fonctionnement d'une IP virtuelle (VIP) à travers différents sous-réseaux (Cluster Mirror)
Orchestration du trafic "Cloud-Ready" via l'intégration d'un répartiteur de charge
En s'appuyant sur l'infrastructure réseau externe, la solution SafeKit Software-Defined High Availability pour les clusters Multi-AZ et Cloud s'intègre de manière transparente avec un répartiteur de charge réseau (Network Load Balancer) pour orchestrer le basculement du trafic entre des sous-réseaux et des zones de disponibilité distincts.
Clusters miroir multi-sous-réseaux : implémentation Windows et Linux
Routage du trafic multi-sous-réseaux via les tests de santé (Health Checks) du répartiteur de charge
Lorsque les nœuds du cluster résident dans des sous-réseaux différents, le basculement standard basé sur l'ARP n'est pas possible. Dans ce scénario, l'adresse IP virtuelle (VIP) est hébergée sur un répartiteur de charge (Load Balancer - LB) plutôt que sur la carte Ethernet du serveur. Le répartiteur de charge agit comme une passerelle, dirigeant le trafic vers les adresses IP physiques des nœuds primaire et secondaire en fonction de leur disponibilité en temps réel.
Routage dynamique via les tests de santé SafeKit
SafeKit gère l'orientation du trafic en fournissant une URL de test de santé (Health Check URL) dédiée sur chaque nœud. Le répartiteur de charge interroge ces URLs pour déterminer l'état du cluster :
Nœud primaire (PRIM) : le test de santé renvoie HTTP 200 OK. Le répartiteur de charge y dirige tout le trafic.
Nœud secondaire (SECOND) : le test de santé renvoie HTTP 404 NOT FOUND. Le répartiteur de charge n'envoie aucun trafic vers ce nœud.
Lors d'un événement de basculement (failover), SafeKit bascule instantanément les réponses des tests de santé, déclenchant ainsi le reroutage du trafic client par le répartiteur de charge vers le nouveau serveur primaire.
⚠️ Note : SafeKit fournit la logique de test de santé ; le répartiteur de charge physique ou virtuel doit être fourni par votre infrastructure réseau.
Intégration Cloud : AWS, Azure et GCP
Ce modèle « Load Balancer + Health Check » est le standard de l'industrie pour la Haute Disponibilité dans le Cloud. Il est essentiel pour l'implémentation de SafeKit dans des environnements tels que :
Considérations réseau : Répartiteur de charge vs LAN étendu
Si l'utilisation d'un répartiteur de charge n'est pas souhaitée, consultez votre équipe réseau pour la mise en œuvre d'un LAN étendu (VLAN stretching) entre les sous-réseaux. Cela vous permet de revenir au modèle VIP plus simple du « même sous-réseau ».
⚠️ Note : Lorsque vous optez pour un répartiteur de charge, vérifiez que votre application est compatible avec la translation d'IP source/destination (SNAT/DNAT). Avec un répartiteur de charge, l'application peut perdre la trace de l'identité de l'utilisateur d'origine ou ne pas démarrer car elle ne voit plus l'adresse IP virtuelle configurée directement sur sa propre interface réseau.
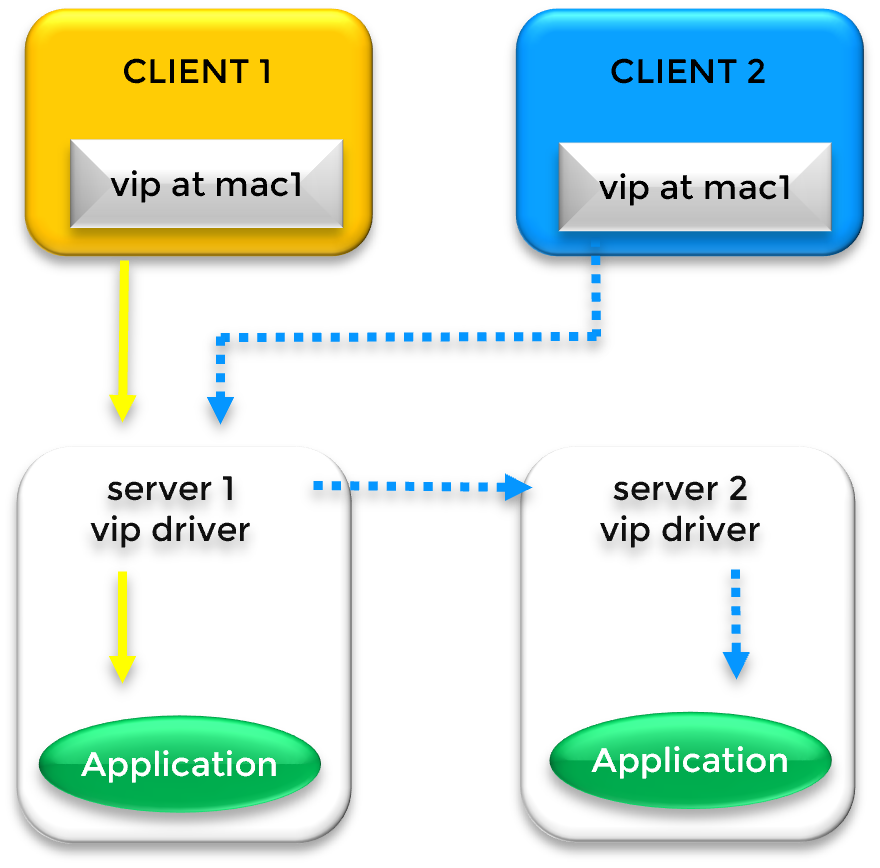
Fonctionnement d'une IP virtuelle avec répartition de charge sur le même sous-réseau (Cluster Farm)
Performance évolutive : Équilibrage de charge au niveau du noyau et redondance
Pour les environnements à fort trafic, le Guide d'architecture : Haute disponibilité évolutive avec clusters de fermes multi-nœuds explique comment SafeKit répartit les charges de travail sur plusieurs serveurs actifs tout en maintenant une redondance totale.
Architecture de cluster de ferme : Équilibrage de charge sur des nœuds Windows ou Linux
Traitement distribué du trafic via filtrage au niveau du noyau
Dans un cluster de ferme avec équilibrage de charge, une adresse IP virtuelle (VIP) est utilisée pour répartir les requêtes clients sur plusieurs serveurs simultanément. Bien que cet exemple présente deux nœuds, l'architecture évolue pour supporter des fermes de serveurs plus importantes. Dans une configuration sur le même sous-réseau, la VIP est configurée sur la carte Ethernet de chaque serveur du cluster via l'aliasing IP.
Distribution du trafic : Le filtre au niveau du noyau
Contrairement à un simple cluster de basculement (failover), un cluster de ferme gère le trafic via un filtre spécialisé au niveau du noyau. Le processus fonctionne comme suit :
Mappage ARP : Dans les caches ARP des clients, la VIP est initialement associée à une adresse matérielle unique (ex: mac1 du Serveur 1).
Fractionnement des paquets : Lorsque le Serveur 1 reçoit le trafic, le filtre noyau SafeKit analyse l'identité des paquets entrants (basée sur l'IP Client ou le Port TCP).
Partage de charge : Le filtre détermine quels paquets doivent être traités localement et lesquels doivent être redirigés vers d'autres nœuds (ex: Serveur 2) pour le traitement, garantissant ainsi une charge de travail équilibrée.
Basculement et routage avec l'ARP gratuit (GARP)
Si le nœud primaire (Serveur 1) échoue, le cluster maintient la disponibilité grâce à l'ARP gratuit (GARP). SafeKit diffuse un message GARP pour mettre à jour les caches ARP des clients avec l'adresse mac2 du Serveur 2. Cela garantit que même si le "point d'entrée" primaire échoue, les clients sont immédiatement redirigés vers les nœuds survivants de la ferme.
Déploiement sur des sites distants
Pour les organisations opérant sur des centres de données distants, cet algorithme d'équilibrage de charge reste fonctionnel à condition que les sites soient reliés via un LAN étendu ou un VLAN. Cela crée un environnement virtuel de "même sous-réseau", qui constitue la configuration la plus efficace pour les clusters de fermes géographiquement distribués.
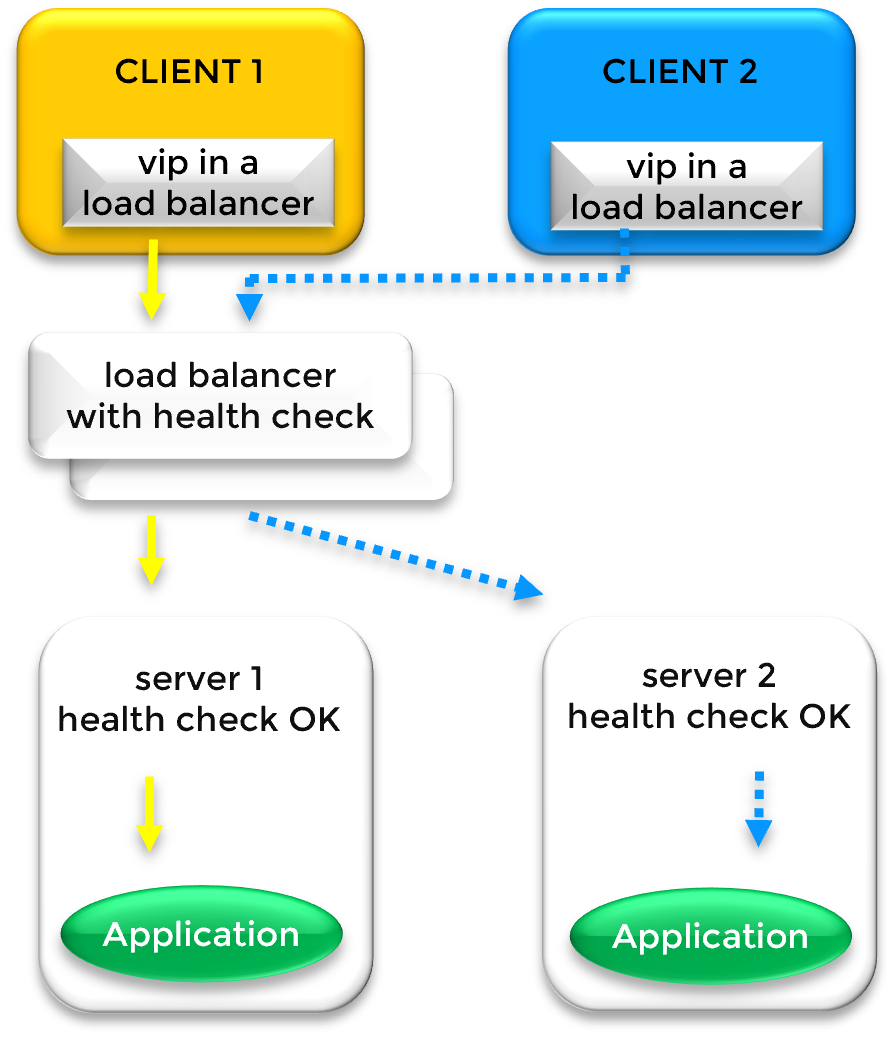
Fonctionnement d'une IP virtuelle avec répartition de charge à travers différents sous-réseaux (Cluster Farm)
Mise à l'échelle Multi-Zone : Orchestration du trafic à travers les sous-réseaux Cloud
Le Guide d'architecture : Mise à l'échelle des clusters de fermes dans des environnements Multi-Zone et Cloud fournit le modèle pour distribuer les charges de travail applicatives sur des zones de disponibilité et des sous-réseaux distincts.
Clusters de fermes multi-sous-réseaux : Évolutivité Windows et Linux multi-nœuds
Distribution du trafic global via l'équilibrage de charge externe
Lorsque les nœuds de la ferme sont répartis sur différents sous-réseaux (courant dans les déploiements cloud Multi-AZ), l'IP Virtuelle (VIP) est gérée par un Load Balancer (LB) externe. Le LB détient la VIP et dirige le trafic entrant vers les adresses IP physiques des serveurs situés dans leurs sous-réseaux respectifs.
Routage intelligent du trafic et règles d'équilibrage de charge
Le Load Balancer distribue les requêtes des clients en fonction de deux facteurs principaux :
Règles de distribution : Le trafic est réparti selon l'affinité de session ou des algorithmes d'équilibrage de charge (par exemple, en analysant l'adresse IP du client ou le port TCP du client).
Disponibilité des nœuds : Le trafic n'est routé que vers les nœuds sains, comme déterminé par le test de santé (health check) SafeKit.
⚠️ Note : SafeKit fournit la logique du test de santé ; le Load Balancer physique ou virtuel doit être fourni par votre infrastructure réseau.
Mécanisme de Health Check SafeKit
SafeKit fournit une URL de Health Check en temps réel sur chaque serveur de la ferme pour communiquer son état opérationnel au Load Balancer :
Nœud UP : Le health check renvoie HTTP 200 OK. Le Load Balancer inclut ce serveur dans la rotation active.
Nœud DOWN/Failover : Si un serveur ou une application échoue, SafeKit renvoie HTTP 404 NOT FOUND (ou le service devient inaccessible). Le Load Balancer cesse immédiatement d'envoyer du trafic vers le nœud défaillant.
Standards de déploiement Cloud : AWS, Azure et GCP
Cette architecture est le modèle fondamental pour les clusters de fermes Cloud, garantissant que si un sous-réseau ou une zone entière devient hors ligne, les nœuds restants continuent de gérer la charge. Ceci est supporté nativement par :
IP virtuelle vs Redirection DNS : pourquoi le basculement DNS échoue souvent
Le piège de la propagation DNS : pourquoi les VIP surpassent la redirection DNS
S'appuyer sur le DNS pour le basculement (failover) crée souvent un sentiment de sécurité trompeur dans les architectures à haute disponibilité. Bien que la modification d'un enregistrement DNS pour pointer vers un serveur de secours semble être une solution de récupération simple, elle introduit une variable critique : une latence imprévisible. Parce que la redirection basée sur le DNS repose sur un écosystème incontrôlé de résolveurs récursifs intermédiaires pour reconnaître et propager le changement, elle est fondamentalement incompatible avec les exigences de « zéro interruption » des services d'entreprise modernes.
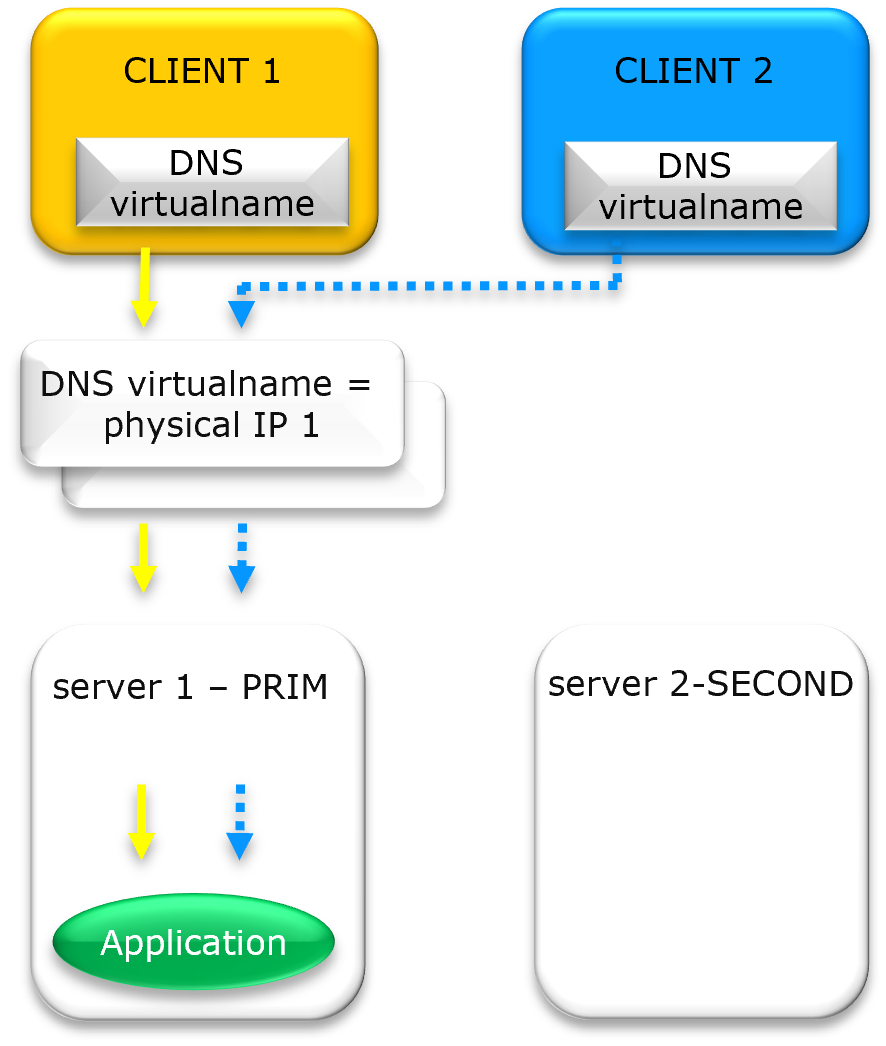
Le scénario technique : résolution DNS et client « bloqué »
Dans une configuration réseau standard, un Nom Virtuel (le nom DNS) fait office de point d'entrée lisible par l'homme pour les utilisateurs. Cependant, pour que les données circulent sur le réseau, ce nom doit être résolu en une adresse IP Physique spécifique.
Résolution DNS et clients « bloqués » sur l'IP physique 1 dans un cluster à haute disponibilité
État actuel : Résolution vers l'IP Physique 1
Initialement, le Client 1 et le Client 2 interrogent le système DNS pour le Nom Virtuel. Le système renvoie l'IP Physique 1. Les clients établissent ensuite une connexion réseau directe (socket) vers cette adresse matérielle spécifique.
Le défi du basculement : redirection vers l'IP Physique 2
Si le serveur à l'IP Physique 1 tombe en panne, un administrateur met à jour l'enregistrement DNS pour pointer vers l'IP Physique 2. Pour rediriger les clients avec succès, une séquence « parfaite » doit se produire :
Le Time to Live (TTL) doit expirer sur tous les résolveurs intermédiaires des FAI et des entreprises.
Le cache DNS local du Client 1 et du Client 2 doit être vidé.
L'application doit fermer son socket existant et lancer une nouvelle requête DNS.
Si l'une de ces étapes échoue, le Client 1 et le Client 2 resteront « bloqués », tentant de communiquer avec l'IP Physique 1 inactive, ce qui entraîne une interruption de service malgré la mise à jour des enregistrements DNS.
Les deux « boîtes noires » de la redirection DNS
Mise en cache récursive : De nombreux fournisseurs d'accès Internet (FAI) et résolveurs DNS d'entreprise ignorent les réglages de TTL bas pour réduire le trafic, mettant souvent en cache l'« ancienne » IP Physique 1 pendant des minutes, voire des heures, au-delà de l'expiration demandée.
Persistance applicative : Les applications modernes (telles que les microservices basés sur Java ou les navigateurs Web) n'effectuent souvent une recherche DNS qu'une seule fois au démarrage. Même si l'enregistrement DNS est mis à jour vers l'IP Physique 2, l'application continue d'utiliser l'IP initiale stockée dans sa mémoire interne.
Conclusion
La redirection DNS est une solution incohérente pour une solution de haute disponibilité. Pour un basculement instantané dans un environnement local ou régional, une IP Virtuelle (VIP) définie par logiciel est le seul moyen de garantir une persistance sans aucune interruption de service.
Comparaison : mise en œuvre de l'IP virtuelle, latence et transparence applicative
Comparaison technique des méthodes de redirection par IP virtuelle (VIP) par rapport au reroutage DNS pour la Haute Disponibilité et la Reprise après Sinistre.
Environnement & Cas d'utilisation
Type de Haute Disponibilité
Mécanisme de Redirection
Latence Réseau
Transparence Applicative & Localité de l'IP
Primaire/Secondaire (Haute Disponibilité)
Cluster Miroir
ARP Gratuit (GARP) / Reprise d'adresse MAC
Très faible : Temps de détection et d'envoi du broadcast GARP
Transparence Totale : L'IP virtuelle est locale sur le nœud actif. L'IP source du client est préservée.
Équilibrage de Charge (Actif/Actif)
Cluster de Ferme
Filtre Réseau au niveau du Noyau / GARP
Très Faible : Temps de détection et de reconfiguration des filtres réseau
Transparence Totale : L'IP virtuelle est locale sur tous les nœuds. L'IP source du client est préservée.
Même Sous-réseau / LAN Étendu (VLAN Stretching)
Reprise après Sinistre (datacenters distants)
Aliasing IP Standard / GARP
Faible : Dépend du RTT (Round Trip Time) du VLAN étendu
Transparence Totale : L'IP virtuelle est locale sur les nœuds. L'IP source du client est préservée.
Sous-réseaux Différents
Reprise après Sinistre (datacenters distants / Cloud)
Équilibreur de Charge Externe (Load Balancer)
Modérée : Latence de basculement plus élevée due aux intervalles de "Health Check" du Load Balancer
⚠️ Transparence Partielle : Utilise SNAT/DNAT. L'IP virtuelle n'est PAS locale sur les nœuds. L'IP source du client n'est PAS préservée. L'application doit supporter ce mode.
Reroutage DNS : Sans VIP
Reprise après Sinistre (datacenters distants)
Mise à jour de l'enregistrement DNS (Nom / IP physique)
Élevée/Imprévisible : Dépend du TTL DNS (Time To Live) et du cache DNS du client.
⚠️ Peu Fiable : Le client doit résoudre à nouveau le DNS. Souvent, les clients continuent d'utiliser l'IP obsolète résolue au démarrage et ne sont pas redirigés après un basculement.
Configuration d'une adresse IP virtuelle pour la répartition de charge et la haute disponibilité
Dans cette vidéo, apprenez à implémenter une adresse IP virtuelle pour fournir un point d'entrée unique à un cluster de 2 nœuds. SafeKit simplifie la répartition de charge réseau en gérant automatiquement l'IP virtuelle, garantissant que le trafic client est distribué entre les nœuds et redirigé instantanément lors d'un basculement.
Foire aux questions (FAQ) sur l'IP virtuelle (VIP)
IP virtuelle (VIP) et Réseau
Qu'est-ce qu'une IP virtuelle (VIP) et en quoi diffère-t-elle d'une IP physique ?
Alors qu'une adresse IP physique est liée à une interface réseau spécifique, une IP virtuelle (VIP) est une adresse "flottante" indépendante du matériel. Dans un cluster SafeKit, la VIP fait office de point d'entrée persistant ; si le serveur primaire tombe en panne, la VIP migre automatiquement vers un nœud secondaire sain, garantissant une disponibilité sans aucune reconfiguration côté client.
Ai-je besoin d'un répartiteur de charge matériel (load balancer) pour utiliser une IP virtuelle ?
Non. Le logiciel de haute disponibilité SafeKit gère l'IP virtuelle au niveau logiciel. Dans les architectures sur un même sous-réseau, il utilise l'IP aliasing et le Gratuitous ARP (GARP) pour rediriger le trafic. Cela élimine le coût et la complexité des répartiteurs de charge matériels externes ou des serveurs proxy dédiés.
Qu'est-ce que le Gratuitous ARP (GARP) et pourquoi est-il utilisé ?
Le Gratuitous ARP (GARP) est une diffusion réseau (broadcast) qui met à jour les tables ARP des commutateurs (switches) et des routeurs. Lors d'un basculement, le nouveau serveur primaire envoie un paquet GARP pour annoncer que l'IP virtuelle est désormais associée à sa propre adresse MAC, forçant une redirection immédiate du trafic sur l'ensemble de l'infrastructure réseau.
Puis-je associer un nom DNS à une IP virtuelle ?
Oui. Vous pouvez associer un nom DNS à une VIP en créant un enregistrement de type A standard. L'avantage majeur est que la redirection est gérée au niveau VIP (via ARP ou redirection réseau) et non au niveau DNS. Cela garantit la transparence applicative en évitant les délais liés à la propagation DNS et à l'expiration du TTL.
Cloud et Architectures Avancées
Comment fonctionne une IP virtuelle dans le Cloud (AWS, Azure, GCP) ?
Dans les environnements cloud où le niveau 2 (ARP) est restreint, SafeKit s'intègre aux Cloud Load Balancers (AWS ELB, Azure LB ou Google GCLB). SafeKit fournit une URL de Health Check que la plateforme surveille pour acheminer le trafic vers le nœud actif via SNAT/DNAT.
Un LAN étendu est-il préférable à un Load Balancer pour le Disaster Recovery ?
Oui. Pour les datacenters distants, un LAN étendu (stretched VLAN) est souvent supérieur car il maintient la transparence applicative entre les sites. En conservant la même IP virtuelle, l'application et ses clients continuent de communiquer via la même identité, rendant la transition entre datacenters totalement transparente.
Quelles sont les limites du basculement DNS par rapport à l'IP virtuelle ?
Le basculement DNS est limité par le TTL (Time to Live) et le cache côté client, ce qui peut retarder la reprise pendant des heures. Un inconvénient majeur est que les clients qui ne réactualisent pas leur résolution DNS restent bloqués en tentant de se connecter au serveur défaillant. À l'inverse, une IP virtuelle offre un basculement de niveau 2 instantané qui redirige tout le trafic immédiatement, quel que soit l'état du cache DNS client.
Transparence et Sécurité
Pourquoi une IP virtuelle locale est-elle importante pour la transparence applicative ?
Une IP virtuelle (VIP) locale garantit la transparence applicative en permettant au logiciel de se lier (bind) à une VIP persistante. SafeKit gère la redirection au niveau du noyau (kernel), laissant l'application ignorer les basculements de cluster, contrairement aux solutions DNAT où l'IP liée change.
L'utilisation d'une IP virtuelle préserve-t-elle l'adresse IP d'origine du client ?
Oui. SafeKit évite la traduction d'adresse réseau source (SNAT). Comme la VIP est locale au serveur actif, l'application reçoit l'IP client d'origine, ce qui est crucial pour l'audit de sécurité, la persistance de session et la journalisation réglementaire.
🔍 Hub de navigation SafeKit Haute Disponibilité
Explorez SafeKit : fonctionnalités, vidéos techniques, documentation et essai gratuit
Type de ressource
Description
Lien direct
Fonctionnalités clés
Pourquoi choisir SafeKit pour une haute disponibilité simple et économique ?
 pour les clusters SafeKit en mode Mirror (failover) et Farm (répartition de charge).")